この記事はcloud.config tech blogにもマルチポストしています。
この記事はcloud.config tech blogにもマルチポストしています。
tech-blog.cloud-config.jp
はじめに
世間ではいろんな人がトレーナーになって馬を走らせているようですがなむゆは相変わらずパイプラインを走らせています。あるいは回しています。
パイプラインを実行することの言い回しって「走る」と「回す」の二つを同じくらいよく聞くのですがこれを読んでいる人はパイプラインは走らせているのでしょうか、回しているのでしょうか気になる今日この頃です。
さて、今回はAzure Pipelineでパイプラインのyamlを書いていてしばらく混乱していたことがあるので整理がてら一席打ちたいと思います。
内容としてはAzure Pipelineのパイプライン定義yamlでよく書く$[]や${{}}、$()といったもの、いわゆるExpressionというものについてです。
Expressions
Expressionは直訳すると「式」になります。
C#のラムダ式(lambda-expression)とか言いますよね。
特殊な記法の式を書くことで、関数を簡単に書いたりなんやかんやするアレです。
で、Azure Pipelineにおいても特殊な記法をする「式」を用いて様々な操作を行うことがあります。
使い方のよくやる例としては以前の記事で共有したvariableやparameterの値の取得があります。
他にもラムダ式のような関数を定義する式も作れたりするのですが、個別の記法はExpressionsのドキュメントを参照してください。
さて、問題はというと、これらの記法は主に3つあり、どれも共通の機能の一つとしてパイプラインで設定した変数を扱うことができるのですが、それぞれ取得できる値や使いどころが微妙に違っていることです。
似たようなものなのでどれか一つの書き方で書こうとしていたら特定の場面では使えなかったりします。
なので、それぞれのExpressionの特徴を把握して使いどころを間違えないようになりましょう。
まず初めにAzure Pipelineで使用できる変数について復習
以前の記事でも取り上げたお話ですが、今回の話で重要なトピックなので最初に軽く解説していきます。
Expressionの使い分けの一つに「どのExpressionではどの変数が呼べるか」という点があるためです。
Azure Pipelineの機能として設定して使用できる変数はよく使うもので3つほどあります。
一つ目はパラメータです。これはランタイムパラメータとも呼ばれ、パイプラインの実行ごとに手動で指定してやるパラメータです。
パイプラインyamlでパラメータを設定しているとAzure Pipelineでパイプラインを実行する際にブランチ名のドロップダウンの下に入力欄が出てくるのでそこで指定します。
二つ目はvariableとして定義するstaticな変数です。これはパイプライン固有の固定値を設定するために用います。
root、stage、jobのレベルのそれぞれのスコープで指定することができ、変数名が被った場合はよりスコープが狭い方が優先されます。
三つ目は、variable groupとして設定する変数です。これはAzure DevopsのLibraryから設定する値で、Libraryからいつでも設定し直せます。じゃあparameterでいいようにも思えますが、parameter程実行ごとに変更するものではない値の設定や、また、variable groupにはsecret属性を持たせることもできるため、parameterとはまた違った目的で利用します。
それぞれの書き方は以下の通りです。
上から順にランタイムパラメータ、 group:の形で書かれているのはvariable groupの名前、 -name と value に分かれているのがstaticのvariableです。
parameters:
- name: "sampleParam"
type: string
displayName: "SampleParameter"
variables:
- group: SAMPLE_VARIABLE_GROUP
- name: SAMPLE_VARIABLE_VALUE
value: sample variable value
${{}}について
${{}} の形で記述されるこのExpressionはTemplate expression、またはCompile time expressionといいます。
msdnのExpressionsのページではCompile time expressionと呼ばれていますが、Define variablesのページではTemplate expressionと呼ばれています。実際はどちらも同じものです。
Compile timeと呼ばれるとおりAzure pipelineが回り始める下準備としてパイプラインyamlから実際の実行プランが作られる段階で、そのExpressionで計算された値(変数の呼び出しをするExpressionだったらその変数の値とか)と置き換えられます。
yamlから実行プランにコンパイルされる際に実際の値置き変えられるので、指定したスコープより内側であればyaml上のどこにでも書くことができます。
取得できる変数は、先程説明した3つの変数のうち固定値のvariableとruntime parameterです。
variable groupの値は取得できません。残念。
書き方としては以下のようになります。
${{ parameters.変数名 }} # runtime parameterから値を取りたい場合
${{ varibales.変数名 }} # 固定値のvariableから値を取りたい場合
$[]について
$[] の形で記述されるこのExpressionはRuntime expressionといいます。
こちらはCompile time expressionとは対照的に変数の値の評価のタイミング、つまりExpressionから実際の値に置き換えられるタイミングは処理の実行時になっています。
つまり、variableの値が以前のtask等で書き替えられた場合、そのExpressionが書かれている処理が行われるタイミングのvariableの値が使用されます。
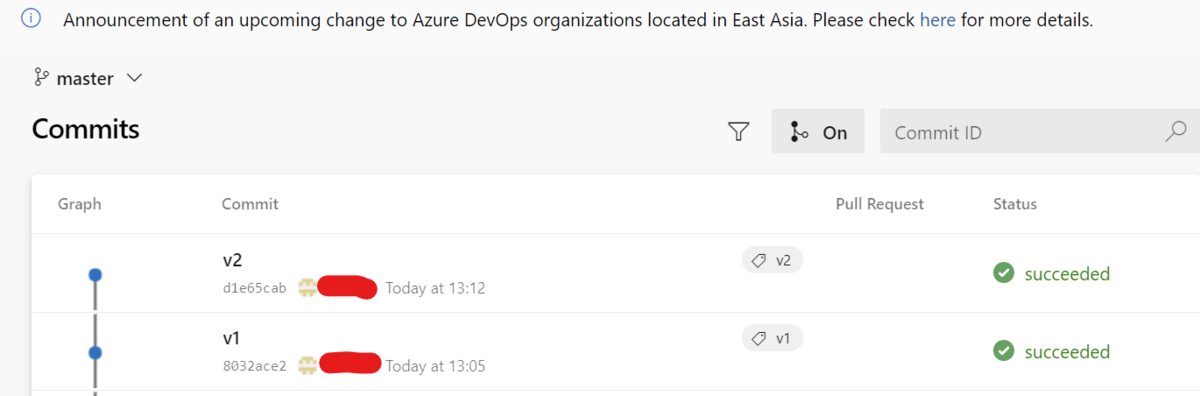
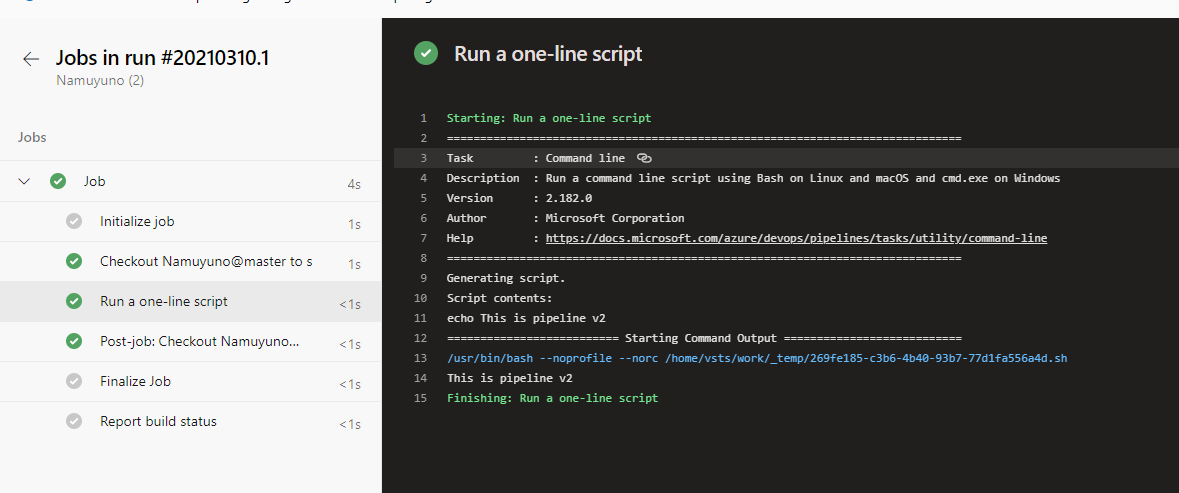
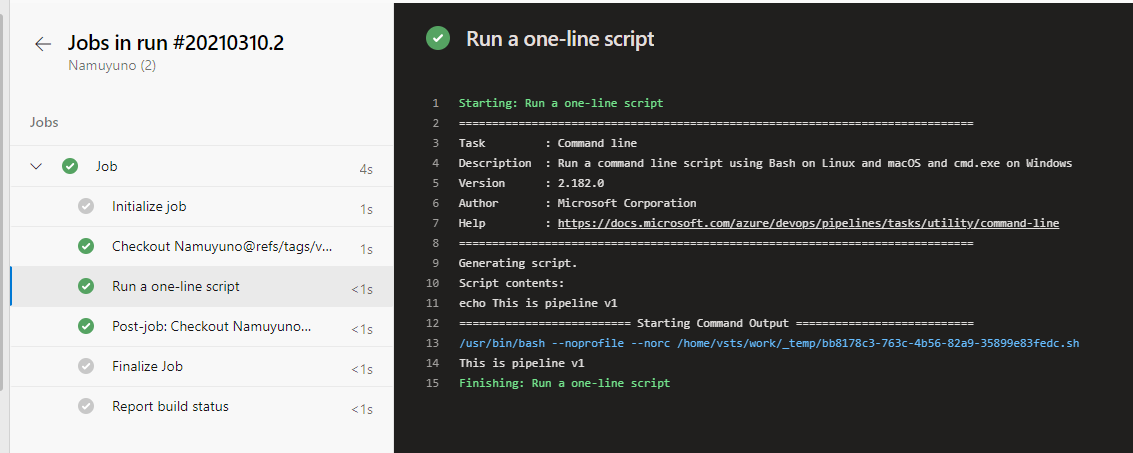
別のタスクでvariableの値を書き換える例はこちらにあります。
このExpressionは使い方に癖があります。
Runtime expressionを使う際は、キーバリューペアの右側全体をカバーしなければならないのです!!!
キーバリューペアの右側全体をカバー・・・?意味が分からないですね。
これはvariableの解説ページのRuntime expression syntaxに書かれていることで、原文では
The runtime expression must take up the entire right side of a key-value pair.
とあります。
これが意味することとしては、例えばvariableの値としてruntime expressionを指定するときに以下のように書きますが・・・
- name: SAMPLE_VARIABLE_VALUE
value: $[variables.sampleval]
この時、 value: $[variables.sampleval] の : を挟んだ右側全体をカバーしなければならないという意味です。なので、例えば以下のような書き方はできません。
- name: SAMPLE_VARIABLE_VALUE
value: sampleval is $[variables.sampleval]
そのexpression以外のものを : の右側に書くとエラーになってしまいます。
他の、例えばCompile time expressionは以下のような書き方ができます。
- name: SAMPLE_VARIABLE_VALUE
value: sampleval is ${{ variables.sampleval }}
後述のMacro expressionでも・・・
- name: SAMPLE_VARIABLE_VALUE
value: sampleval is $(sampleval)
というように書けます。
使えるタイミングとしてはvariableとconditionのキーバリューペアになるそうなのですがvariableの値の指定に使うのはちょっと不便ですね。
ちなみにconditionのキーバリューとはstageやjobに対して設定できる値で、この値がtrueの場合のみそのstageやjobを実行するといった動作を指定できます。
これを使用して、「前の処理が成功した場合のみこの処理を実行」というようなロジックを組み込むことができます。
実際にcondition内でどのような判定ロジックを組み込むかはSpecify conditionsのドキュメントを参照です。
今回は変数の取得周りに話を限って解説しています。この辺りは一旦話を広げ始めると無限に広がってしまうのですよ・・・
なお、取得できる変数は、先程説明した3つの変数のうち固定値のvariableとvariabe groupで指定されているvariableです。
runtime parameterの値は取得できません。Runtime Expressionなのにruntime parameterの値を取得できないとはこれいかに。
書き方としては以下のようになります。
$[varibales.変数名] # 固定値のvariable、variable groupのvariable 共通
$()について
$() の形で記述されるこのExpressionはMacro expressionといいます。
Macro expressionはパイプラインの中で、それぞれのタスクが実行される前に評価されて実際の値に置き換えられます。
こちらもCompile time expressionと同じく、適切なスコープ内でなら基本的にどこでも使えるのですが、一部Runtime Expressionと同じような制限を受けるところがあります。
それは、キーバリューペアの中では : の右側にしか書けないということです。yamlがコンパイルされ、プランとしては出来上がった後で評価されるため、プランの構造自体は操作できない・・・というような意味合いかと個人的には考えています。
ただ、前述のとおりRuntime Expressionとは違って : の右側であれば別の文字列の中に混ぜて記述することも可能です。
なお、取得できる変数は、先程説明した3つの変数のうちRuntime expressionと同じく固定値のvariableとvariabe groupで指定されているvariableです。
runtime parameterの値は取得できません。その場合はCompile time expressionを使いましょう。
書き方としては以下のようになります。
$(変数名) # 固定値のvariable、variable groupのvariable 共通
変数名を直接書ける分シンプルですね。
まとめ
表にしてまとめると以下のようになります。
| Expression名 |
書き方 |
variablegroupの値が取れるか |
variableの固定値が取れるか |
parameterの値が取れるか |
評価タイミング |
使用可能箇所 |
注意点 |
| template expression |
${{ parameters.パラメータ名 }}
または${{ variables.変数名 }} |
x |
o |
o |
コンパイル時 |
どこでも(スコープが適切であれば) |
別名: Compile time expression |
| runtime expression |
$[variables.変数名] |
o |
o |
x |
実行時 |
variableとconditionの定義箇所 |
定義の右側全体をカバーする必要あり |
| macro expression |
$(変数名) |
o |
o |
x |
タスク実行前 |
タスクの定義内 |
定義の右側にのみ書ける |
また、これらのExpressionの評価順はcompile time expression -> macro expression -> runtime expression となっています。
評価タイミングがやってくる前にvariableの値に変更があった場合、評価のタイミングが早い別のexpressionとは違った値が取得される可能性がありますので、ユースケースによっては色々利用できます。
おわりに
今回はAzure pipelineのExpressionについて、変数の取得方法の話と絡めて共有しました。
Expressionについてはよく使うユースケースとしてはパイプラインの変数の取得なのですが、実は本来それだけのためのものでないという話や、評価タイミングについてはそもそもパイプラインyamlからどのようにしてパイプライン実行されるかという話と絡んでいたりするという話もあったりして、切り口によって無限に話が膨らんでいってしまうので説明はすごく難しいです。
今回のこの記事も何度も「ややこssssssっし!!」と呟きながら纏めていました。
少なくともよく気になる観点については纏められたかなと思うので、少しでもお役に立てれば幸いです。
参考
- Devine Variables
Variableとそれを使うExpressionの解説はこちら。
ここでは${{}}のことはTemplate expressionと呼ばれています。
- Expressions
Expressionそのものについての解説はこちら。
ただし、こちらではmacro expressionについての解説はありません。なんで。
- Specify conditions
Runtime expressionの使いどころであるconditionの解説はこちら。
- Add & use variable groups
Variable Groupに関する解説はこちら。
Azure Devops上でvariable groupを編集、追加する方法はCreate a variable groupの章のClassicタブにあります。
- Runtime parameters
Runtime parameterについての解説はこちら。
- YAML schema reference
Azure Pipelineの処理の内容を定義するパイプラインyamlの全体的な書き方はこちら。
特に、stage、job、stepといった階層の話はvariableの指定、使用できるスコープの話と関連するので、variableについて調べるなら併せて読むと理解が深まるかと思います。