この記事はcloud.config tech blogにマルチポストしています。
この記事はcloud.config tech blogにマルチポストしています。
tech-blog.cloud-config.jp
はじめに
最近ずっとkubernetesの勉強しているなむゆです。
特にここ4週間くらいはIstioについて重点的に動かしたり資料を読んだりしていたのでその時に学んだ基礎的な点を記事にまとめておきたいと思います。
istioとは
Istioとは、高機能なオープンソースのサービスメッシュです。
Kubernetesのようなプラットフォームにインストールして使用され、内部にサービスメッシュを展開します。
現在はKubernetesのほかに、HashiCorpによってつくられたサービスディスカバリのConsul、または個別の仮想に対応しています。
サービスメッシュとは
「高機能なサービスメッシュ」と書きましたが、ではそのサービスメッシュとは何かというと、マイクロサービスアーキテクチャのようなサービスを複数展開し、相互に連携して全体の機能を実現しているときにそれらのサービス間のネットワークを仲介する機能です。
例えば、サービス間で通信したいとなった際に通信相手のサービスの名前解決を行ったり、それらの通信に失敗したときのリトライ機能などを基本的な機能として持ちます。
これにより、マイクロサービスアーキテクチャにおいて課題になりがちであった、サービス間の通信の障害や通信が増えることによる性能劣化といった問題を解決し、マイクロサービスアーキテクチャを実現しやすくしてくれます。
実際にどんな実装が行われていてどんな機能が実現されているかはサービスメッシュによって差があります。
これがあると何がうれしいの?
Istioはそんなサービスメッシュを実装しているもののうちの一つです。
これがなくてもkubernetesにおいてリクエストやkubernetes内のネットワークを構築することはできなくはないのですが、サービスメッシュを使うとその仕組みをより高機能に、より簡単に実装できます。
例えば、クラスター内の通信について、リトライ処理を追加したりA/Bテストを行う時に使うような割合でトラフィックを分割する仕組み、リクエストのタイムアウトの時間などを設定できます。
それらの通信についてメトリクスやログを取ることもでき、kialiやgrafana等の可視化ツールと連携してネットワークの監視を行うこともできます。
これらの機能をいくつかの設定を行うだけで実現できるのがサービスメッシュの強みになります。
詳しい個別の情報についてはドキュメントをどうぞ。
ドキュメントが英語なのと個別に見ていくとキリがないので分かりやすい粒度でまとめてみます。
Istioのサービスメッシュは大きく分けるとData Planeという部分とControl Planeという部分に分かれます。
これらはオブジェクトとして物理的にわかれているものではなく概念的な分類なのですが、それぞれでIstio内で担う役割が違います。
Data Plane
まずData Planeなのですが、こちらは外部からやってきたものやサービスの間で交わされる通信を実際に行う役割を担います。
具体的には、Envoyと呼ばれるリソースがあり、これがkubernetes内に立てられるサービスごとにペアとなるように作られます。
このペアのように作られる様子をサイドカーと呼んだりします。バイクに対するサイドカーのように、サービスごとに横付けされるように作られるためです。
で、これが何をするものなのかと言うと、例えるなら家ごとに置かれた郵便受けやポストのようなものになります。
具体的には、他のサービスやkubernetes外部と送受信を行うプロキシになります。
外部からやってきた通信はまずEnvoyに届き、プロキシが横付けしたサービスにその内容を伝えます。
また、外部に対する通信もサービスからEnvoyに送り、そこから他のサービスやkubernetes外部に内容が送られます。
年賀状も家に届くときはまず郵便受けに届いてそこから取り出しますし、送るときは送り先に直接届けるのではなくポストに投函しますよね。
Envoyもそのような役割を果たし、ネットワーク関連の言葉で言うとプロキシの役割を果たします。そしてそれはサービス毎にサイドカーとして作られ横付けされたサービスに対するプロキシになるわけです。
また、Envoyを通して通信を行うことで通信時のトラフィックの統計情報を収集する役割もあります。
Control Plane
Control Planeは、そんなData Planeを制御する役割を持ちます。
代表的な例としてはどんなurlのリクエストがやって来たらどこのサービスにそのリクエストを送り届けるかといったルーティングをVirtual Serviceを用いて行うというものがあります。
これによってkubernetes外部からやってきたリクエストをどのサービスに渡すかを制御します。
他にも、kubernetes内のサービス間での通信を制御し、通信時にルールを設定することでセキュリティの機能を実装することもできます。
これらの機能は、細かく分けるとさらにPilot(Istioの通信制御等のルールをEnvoyに伝えたりその他便利機能)、Citadel(証明書周り)、Galley(Istioに対して行う設定受けつけ)といった部分に分かれますが、今は全部まとめてIstiodというものにまとめられているようです。
なので、IstiodはEnvoyの制御を行うControl Planeの役割を大体になっているようなイメージになります。
ざっくりした動作の流れ
ここまでIstioの個別の部分の説明してきましたが、それだけだとそれを使ってどのような流れの処理になるのかイメージしづらいので、外部からリクエストがやってきてそれに対してレスポンスを行うまでの流れをざっくりと解説してみます。
全体の図としてはこのようになります。マイクロサービスアーキテクチャを採用しているのでサービスは複数あり、それぞれにEnvoyがサイドカーとして横付けされています。
この中で、EnvoyはData Planeに属しています。
この図の中で、黄色い付箋はそれぞれ一個のpodになります。

kubernetesにリクエストがやってきました!
まずはこれをIngress Gatewayが受け取ります。
Ingress Gatewayはkubernetes外部からやってくるリクエストの窓口で、ここからVirtualServiceのようなオブジェクトで設定したルールに応じて各種内部のサービスにリクエストを送り届けます。

というわけで今回はサービスAにリクエストを送りたいのでサービスAにサイドカーとして横付けされたEnvoyにリクエストが届きました。

EnvoyはそれをサービスAに渡します。

今回の処理ではサービスBでの処理も行わなければならないため、サービスBに対しても通信を行います。
その際にも、まずはEnvoyと通信し、そこからサービスBへ通信を行います。

サービスBでも同様に、まずEnvoyが通信を受け取り、それをサービス本体に渡します。
こうしてサービスAとサービスBの通信が実現します。

サービスBでの処理が終わればまたEnvoyを通して処理結果をサービスAに返し・・・
サービスAはegress gatewayを経由してリクエスト元のkubernetesクラスター外にレスポンスを返します。

これがIstioを用いてkubernetes内で通信を行う一連の流れになります。
実際にはさらにDBなどkubernetes外部のリソースと通信するために何度もegress gatewayを用いて通信を行ったりもします。
あれ、Control Planeは?
・・・本当はさらにControl Planeもこれらの処理に一枚噛んでいます。
同時に説明すると一つの動作の説明が増えるので章を分けました。
先程の例でのControl Planeの役割を説明します。
例えば、Ingress gatewayにやっていたリクエストをどのサービスに渡すかのルーティングの制御をControl Planeが行います。
VirtualServiceに設定したルーティングのルールに従い、ingress gatewayで受け取ったリクエストをどのサービスに渡すかを決め、Envoyに対してリクエストを送らせるようにします。

また、サービスAとサービスBの間の通信において認証、認可の機能が必要になった場合のそれらの仕組みもControl Planeで実装します。

他に、DestinationRuleやVirtualServiceを操作してサービスのバージョンアップを行う際のBlue/Greenデプロイやサーキットブレイカーなどを実装したりもします。

こうした形でControl PlaneはData Planeを裏から制御する振舞いをしています。
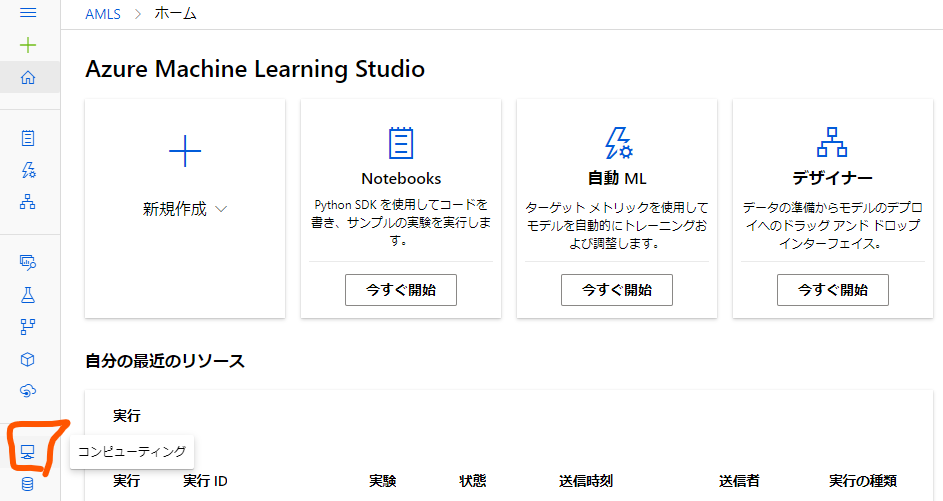
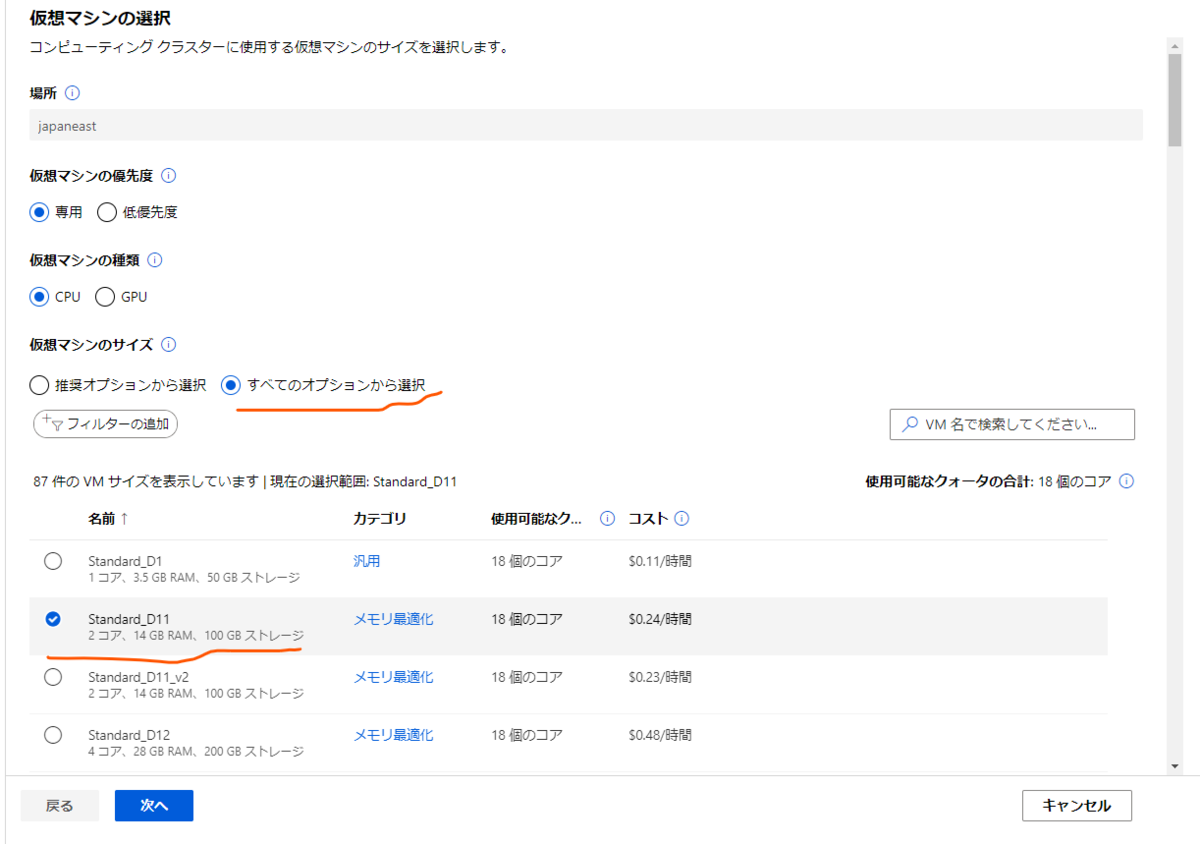
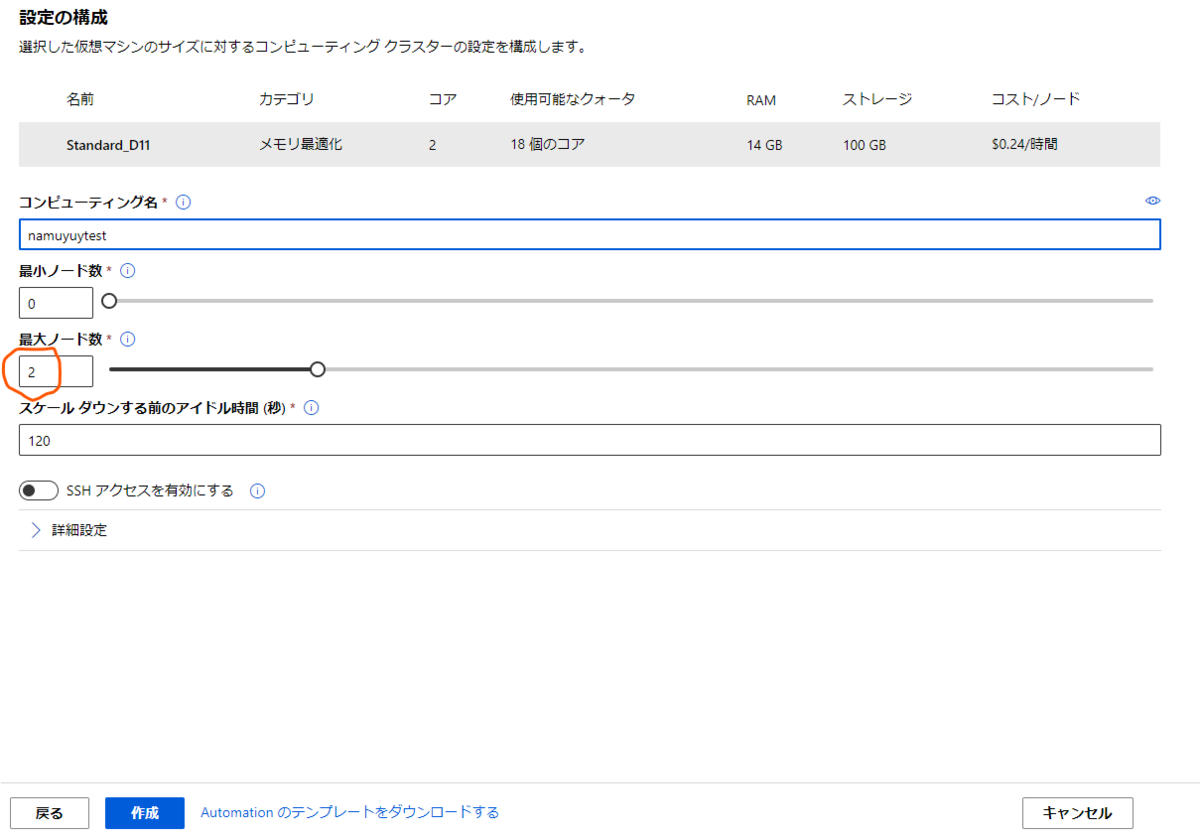
インストール方法
それでは実際の使い方を説明していきます。
環境としてはWindows 10 HomeのOSのPCにDocker DesktopのKubernetes機能で立てたシングルノードのkubernetesを使用します。
導入方法はこちらでまとめているので、まだ導入していない場合はこちらを参考にどうぞ。
導入されたらば、次に進みます。
まずはPC上にIstioctlをダウンロードしてきます。
こちらのサイトの「istioctl-(バージョン)-win.zip」をダウンロードしてきて解凍します。
解凍したらば、分かりやすい場所に移動してそのディレクトリにPathを通します。
Pathを通してistioctlが使用できる状態になれば、インストールする対象のクラスターを現在使用しているコンテキストに指定します。
例えばDocker Desktopで立てたkubernetesにインストールする場合はPowerShell等で下記のようなコマンドを実行します。
kubectl config use-context docker-desktop
コンテキストを切り替えたら、下記のコマンドで現在のコンテキストで接続するクラスターにistioをインストールします。
istioctl install --set profile=default -y
「profile=○○」という部分によって、インストールされる内容が変わります。defaultのほかにdemo、minimal等があり、それぞれのセットアップの内容はこちらに解説があります。
weatherforecastアプリをデプロイしてみる
ここからはIstio公式サイトのGetting Startedをベースに、.net coreアプリをkubernetes上にデプロイして動かしてみます。
Getting Startedではサンプルのアプリケーションとしてbookinfoアプリを動かしてみていますが、今回は普段触れることの多いので.net coreアプリも同様にデプロイできることを示すため以前のブログで作成したweatherforecastのアプリをデプロイしてみます。
そのため、アプリケーションを作成する部分については上記のブログを参考にしながら作成していることが前提となります。
手順2まで済ませたら、こちらの手順に合流しても大丈夫です。
docker buildする際にはあとでタグが分かりやすくするために以下のコマンドでビルドします。
docker build -t weather-forecast:weather-forecast .
コンテナが作成できたら、アプリケーションをデプロイしてIstioを用いてルーティングを行うためのマニフェストファイルを作成していきます。
以下の3つのyamlコードをコピーして同じディレクトリのファイルに保存してください。
apiVersion: v1
kind: Namespace
metadata:
name: weather-forecast
labels:
istio-injection: enabled
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: weather-forecast
namespace: weather-forecast
spec:
selector:
istio: ingressgateway # use istio default controller
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "*"
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: weather-forecast
namespace: weather-forecast
spec:
hosts:
- "*"
gateways:
- weather-forecast
http:
- match:
- uri:
exact: /weatherforecast
route:
- destination:
host: weather-forecast.weather-forecast.svc.cluster.local
port:
number: 80
apiVersion: v1
kind: Service
metadata:
name: weather-forecast
namespace: weather-forecast
labels:
app: weather-forecast
service: weather-forecast
spec:
ports:
- port: 80
name: http
selector:
app: weather-forecast
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: weather-forecast-v1
namespace: weather-forecast
labels:
app: weather-forecast
version: v1
spec:
replicas: 1
selector:
matchLabels:
app: weather-forecast
version: v1
template:
metadata:
labels:
app: weather-forecast
version: v1
spec:
containers:
- name: weather-forecast
image: weather-forecast:weather-forecast
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
yamlファイルを作成できたら、PowerShellを開きます。
上記の3ファイルを置いてあるディレクトリまで移動しておいてください。
移動出来たら、そのディレクトリにある3つのマニフェストファイルをkubernetesに適用します。
kubectl apply -f .
これで作成したマニフェストファイルが適用され、指定したオブジェクトが生成されます。
一番重要なアプリケーションのPodが動作しているかどうかは以下のコマンドで確認できます。
kubectl get pods -n weather-forecast
STATUSの欄がRunningになっていればデプロイに成功しています!
デプロイに成功したら、このAPIを叩いてみましょう。
ブラウザを開き、URLの入力欄にlocalhost:80/weatherforecastと入力してアクセスできます。
Json型のレスポンスが返ってくれば成功です!
このURLにアクセスすると、Gatewayで指定したとおり、80番ポートからkubernetesにリクエストが入ります。
それからIngressGatewayにおいてVirtualServiceに設定したとおりに/weatherforecastのパスにやってきたリクエストはweather-forecast.weather-forecast.svc.cluster.localのhostに送られます。
このhostはこちらで解説されているように、{サービス名}.{namespace名}.svc.cluster.localのルールに従って名前解決されるので、weather-foreastのnamespaceのweather-forecastサービスにリクエストが流れます。
weather-forecastのnamespaceのweather-forecastサービスにはDeploymentのオブジェクトで指定したとおりWeatherForecastのアプリのPodが結び付けられているので、めでたくリクエストはWeatherForecastのアプリケーションにたどり着きます。
このようにして、Istioを使用して通信のルーティングを行うことができます。
おわりに
今回はIstioの基本的な点を説明しながら、実際に動かせるアプリケーションを立てる方法を説明しました。
以前のkubernetesの学習環境の導入方法やアプリのコンテナのビルドの方法と合わせることで、アプリケーション開発~kubernetes上でサービスを利用可能にするするまでの一連の作業が順を追って理解できると思うので、Istioだけでなくkubernetes出のアプリの開発、運用の基本的な方法を知りたいという方はこれらの過去記事もご覧ください。
参考
 この記事はcloud config tech blogにもマルチポストしています。
この記事はcloud config tech blogにもマルチポストしています。