【もっそい小ネタ】Azure PipelineのAPIでリポジトリのtagを指定してパイプラインを実行

この記事はcloud.config tech blogにもマルチポストしました。
はじめに
以前の記事で、Azure PipelineのAPIからパイプラインの実行ができることを共有しました。
今回は、その際にgit上のタグを指定することで指定したタグのコミットの時点のコードを使ってパイプラインを実行できることを共有します。
CI/CDパイプラインを実行する際に開発中のアプリケーションの特定のバージョンのものをデプロイしたいこともあるかと思いますが、gitのタグを利用することが一つの方法になるかと思います。
リポジトリのtagを指定してパイプラインを実行する
さっくりパイプラインyamlを作成、更新するコミットをmasterブランチに打ち、それぞれのコミットに以下のようなタグを振りました。
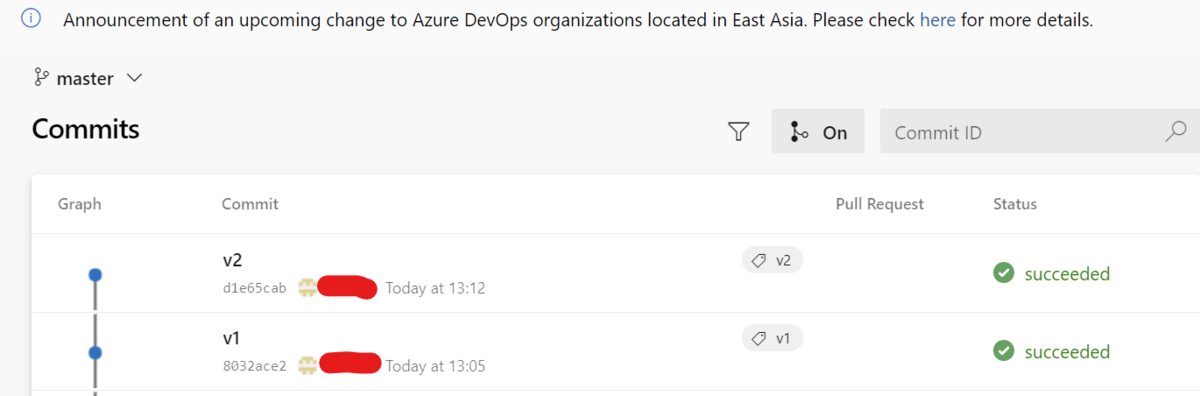
ちなみにパイプラインyamlの中身は以下のようになっています。
trigger: - none pool: vmImage: ubuntu-latest steps: - script: echo This is pipeline v2 displayName: 'Run a one-line script'
v1のコミットにおいては、 - script: echo This is pipeline v2 の行が - script: echo This is pipeline v2 になっています。
それでは、まずは以下のリクエストをbodyに入れてパイプラインを回すAPIを叩いてみます。
Azure Pipelineを回すAPIの叩き方はこちらで紹介しています。
{
"resources":
{
"repositories":
{
"self":
{
"refs/heads/master"
}
}
}
}
結果はこのようになりました。
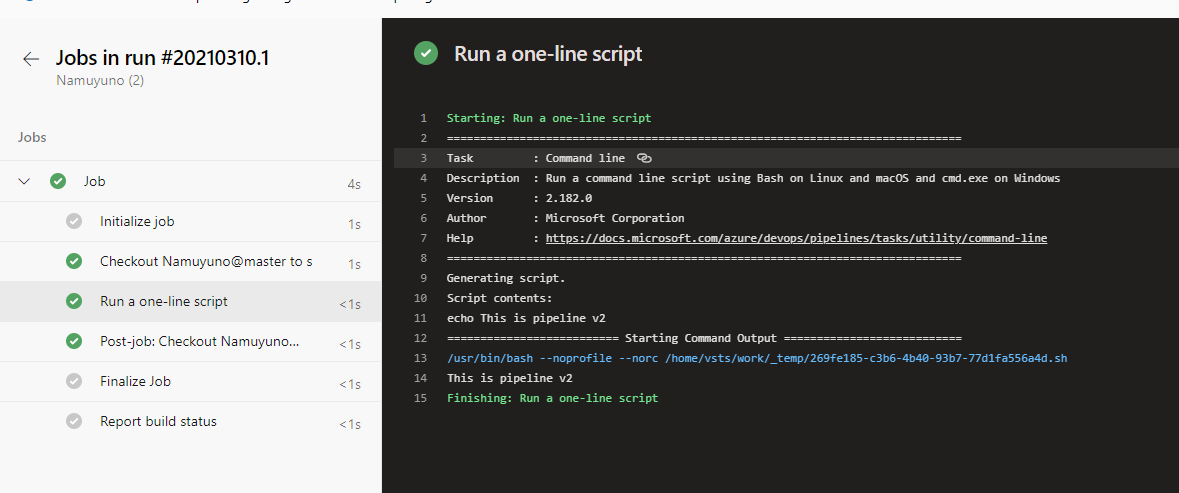
masterブランチの先端のコミットの状態のpipeline.yamlが読まれ、 This is pipeline v2 のメッセージが表示されていますね。
それでは次は、リクエストボディを以下のようにしてリクエストを送信します。
{
"resources":
{
"repositories":
{
"self":
{
"refName": "refs/tags/v1"
}
}
}
}
しばらく待って・・・・パイプラインが回りました。
結果を見てみましょう。
パイプラインの実行結果一覧では今回の実行ではv1のタグが付いたコミットを使用している表示がされています。

また、実行結果の詳細画面では・・・
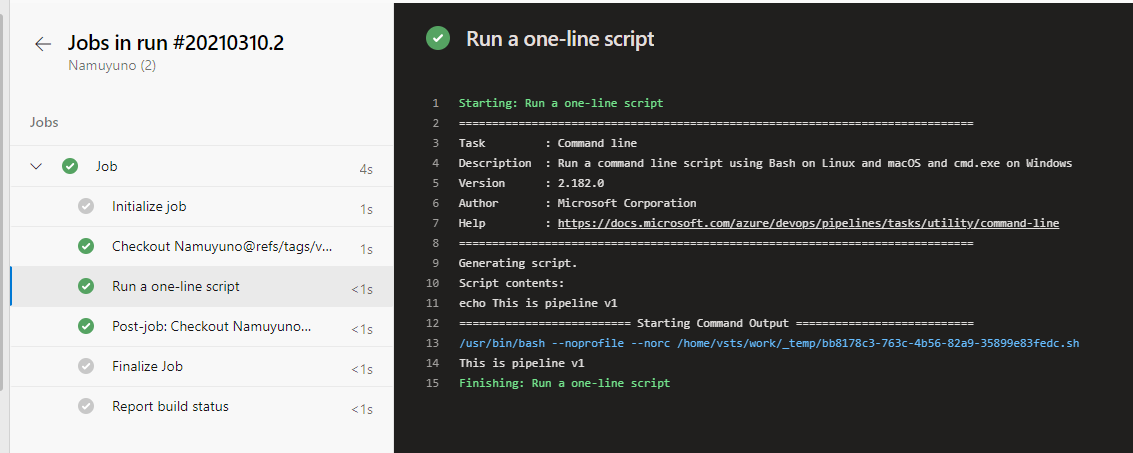
This is pipeline v1 と表示されていますね。
指定したタグのコミットのコードがパイプラインで使用されていることが確認できました。
この状態ならpipeline.yaml以外のコードもこのコミットの状態のものなので、タグを指定することでアプリケーションのコードも固定することができます。
これを用いることはデプロイするアプリケーションのバージョンを管理する方法の一つとして使えるかと思います。
おわりに
今回はAzure Pipelineを実行するAPIの話を土台に、gitのタグをリクエストで指定してやることでそのタグのコミットのコードが使用できることを共有しました。
と言っても、肝なのはリクエストに含まれる「refName」のパラメータ一つなので、今回は小ネタとして共有しました。
幸せなCI/CDライフを!
【Ignite2021】Ignite併設イベントで技術学習するついでに無料でマイクロソフト試験が受けられるらしいんよ~

この記事は後ほどcloud config tech blogにもマルチポストしました。
はじめに
おつかれさまです。調子どうですか~。
最近仕事中に雑談するときはいつもそういって話しかけてるなむゆです。
人に話しかけるのになんて言って話しかけたらいいかずっと分からずに人垣の後ろから覗き込むだけだったキョロ充はこれで卒業できした。
と言っても実際にはキョロ充は精神的には一生キョロ充なので本当は卒業の概念などなく、生涯その枷をはめて生きていくしかないのでそれができたところでってところはあるのですが。
精々自分はまるでそうではないかのように振舞うことしかできないのですがそれをやると今度は自分のやることなすことがどこか嘘っぽく感じて無限にみじめになるのです。
さて、今年もIgniteが始まりました。
昨日は家に帰ってセッション見るぞと思ったのですが会期中は生放送を見るか、それを逃したらオンデマンドで見れるようになるまで生放送から24時間ほど待たなければならないようです。
そんなわけで昨日の夜に見たのはMicrosoft現CEOサティアナデラのkeynoteくらいだったりします。
あとは気になるセッションをお気に入りに入れて後でオンデマンド公開されるのに備えたりしてました。
ただ、それ見るだけと味気ないのと夕飯を食べ終わる前にセッションが終わってしまったのでイベントサイト内をうろうろしていたのですが面白そうな一角があったのでそこについて紹介です。
Microsoft Ignite Cloud Skills Challengeで一人一枚無料で試験オファーを入手できるそうよ
Microsoft Ignite Cloud Skills Challengeは、Microsoft Igniteに併設されたMicrosoft関連技術の学習キャンペーンです。
Microsoft関連技術の学習コンテンツであるMicrosoft Learnの教材を用いて、Microsoft Igniteで触れられた技術の分野ごとに作られたChallengeをこなしていくことによって、その分野の技術を習得しませんかということです。
【 #MSIgnite に参加 & 自習で認定試験を受けよう】
— Microsoft Tech (@msdevjp) 2021年3月3日
「Microsoft Ignite Cloud Skills Challenge」では、7 つのコースから選んで学習課題を受けられます。
3/30 (火)までにコースを完了すると、対応した認定資格試験の特典をプレゼント!
各コースは日本語で受講できます。https://t.co/2KzGt4jFaM pic.twitter.com/5K9A3u1PXU
Challengeは7つあります。興味のある分野を触ってみましょう。↓
- Microsoft Ignite Microsoft 365 Enterprise Admin Challenge
- Microsoft Ignite Azure Admin Challenge
- Microsoft Ignite Azure Data Scientist Challenge
- Microsoft Ignite Teams Admin Challenge
- Microsoft Ignite Data Analyst Challenge
- Microsoft Ignite Identity + Information Protection Challenge
- Microsoft Ignite Security Operations Analyst Challenge
また、このキャンペーンの参加には特典があって、それがMicrosoft認定試験の試験オファーになります。
このオファーを使うことで、一定の範囲内の試験を一回無料で受けることができます。
Microsoft認定試験は普通に受けようとすると普通2万円ほどかかるので、こういったキャンペーンを利用して受けておくのは結構お得感があります。
細かいルールはこちらのページにデ〇ノート裏表紙のHow to use itよろしくまとめられています。
以下重要そうな項目をピックアップ。
- The Microsoft Ignite Cloud Skills Challengeは3月2日の世界標準時午後4時から3月30日世界標準時午後4時まで開催されています。
- Challengeをいくつこなしても受け取れるオファーは一回分だけです。
- オファーの引き換えができるのは021年4月7日から2021年6月30日までです。
- 引き換えられる対象の試験は以下の通り。
- AZ-104: Microsoft Azure Administrator
- DP-100: Designing and Implementing a Data Science Solution on Azure
- MS-700: Managing Microsoft Teams
- MS-100: Microsoft 365 Identity and Services
- MS-101: Microsoft 365 Mobility and Security
- DA-100: Analyzing Data with Microsoft Power BI
- SC-200: Microsoft Security Operations Analyst
- SC-300: Microsoft Identity and Access Administrator
- SC-400: Microsoft Information Protection Administrator
また、ページの下部によくあるQ&Aもあるので目を通しておくといいかと思います。
以下重要そうな内容をピックアップ。
ただ、確実を期すために一度は直接見た方がいいと思います。
- 会期内に一つでもchallengeを完了していると、登録しているMicrosoft Learnのプロファイルに2021年に4月7日に無料試験が関連付けられます。
- チャレンジ登録前にLearnで該当する教材を完了していれば、Challengeの登録後しばらくすると進行状況に反映されます。
Microsoft Ignite Cloud Skills Challengeの始め方
Igniteのページからアクセスする場合は、ページ上部「Learning Zone」から「Cloud Skills Challenge」を選択することでCloud Skills Challengeのトップページに移動できます。
あるいは、こちらのリンクから移動できます。
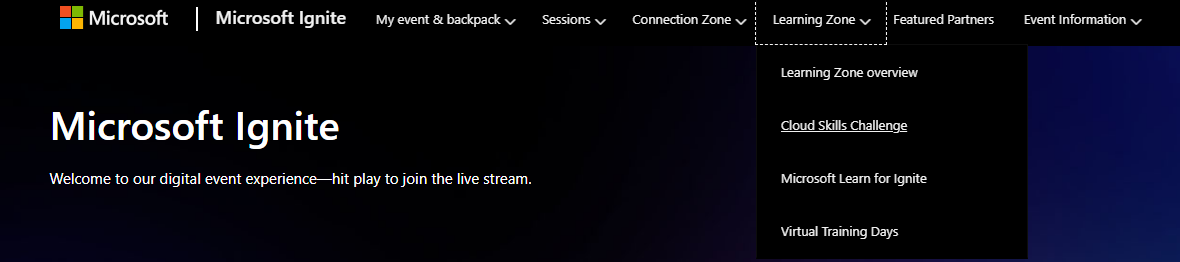
トップページを下にスクロールしていくと、前述の7つのChallengeがあるのでそのうちのどれかしら興味のあるChallengeの「Go to challenge」をクリックします。

いずれかのchallengeのページに移動したら、「チャレンジに参加する」ボタンをクリックします。
このタイミングでMicrosoftアカウントでログインしていなければ、ログインしておきます。
ログインすると、Cloud Skills Challengeの通知用メールアドレスと今いる国を設定します。ここにCloud Skills Challengeの各種お知らせが届きます。
これで登録完了です。
ほら、褒められてますよ。よかったですね。
「学習の開始」をクリックするとそのchallengeのページに遷移し、「学習を続行する」のボタンから対応するLearnが確認できるので一つ一つ完了させていきましょう。
個人的にはこの「すごいですね」とかLearn完了時の「やりま
したね」がツボです。なんで「やりま」と「したね」の間に行替えがあるかは実際にLearnをやってみると分かると思います。
おわりに
今回はIgnite 2021に併設されたイベントのCloud Skills Challengeについて共有しました。
ちなみに私はMicrosoft Ignite Azure Data Scientist ChallengeをやってDP-100を受けようかと考えています。
最新のMicrosoft技術を学んでさらにその知識で受けられる認定試験の無料オファーが入手できるらしいので、お時間と興味がある方はぜひチャレンジしてみてください。
参考
Azure Machine Learningで作ったモデルをAKSにデプロイしてみる

この記事はcloud.config tech blogにもマルチポストしていまます。
はじめに
以前、Azure Machine Learningで回帰モデルを作成するやり方について記事を書きました。
機械学習でモデルをトレーニングしたら、それを何らかのアプリで使用できるようにする必要があると思います。
Azure Machine Learningでは、そのモデルをアプリとしてデプロイして利用する方法が整備されていて、それを利用することで作成したモデルをWebAPIで簡単に利用できるようになります。
今回はその方法の共有です。
回帰モデルを作成してAKSにデプロイする
それでは実際に手を動かしていきます。
以前の記事で作成したAzure Machine Learningのリソースやモデルがあればそれを利用してもいいですが、今回は今回でリソースの作り方から解説していきます。
Azure Machine Learning リソースを作成する
まずは前回同様Azure Machine Learningのリソースを作成します。
ポータル画面上部の検索窓から「Azure Machine Learning」を検索し、青いフラスコみたいなアイコンの「Machine learning」を選択します。
画面左上の「+追加」をクリックしてリソースの作成画面に入ります。
リソースの作成画面では適当なワークスペース名を設定します。
リージョンは基本的に今作業している地域から近い場所が望ましいですが、後述の理由で別のリージョンを設定した方がいい場合もあります。
それ以外は基本そのままで「確認及び作成」ボタンをクリックし、検証されたら「作成」をクリックしてリソースを作成します。
しばらく待ってリソースが作成されたらそのリソースに移動し、「スタジオの起動」ボタンを押してスタジオ画面に移動します。
コンピューティングクラスターを作成する
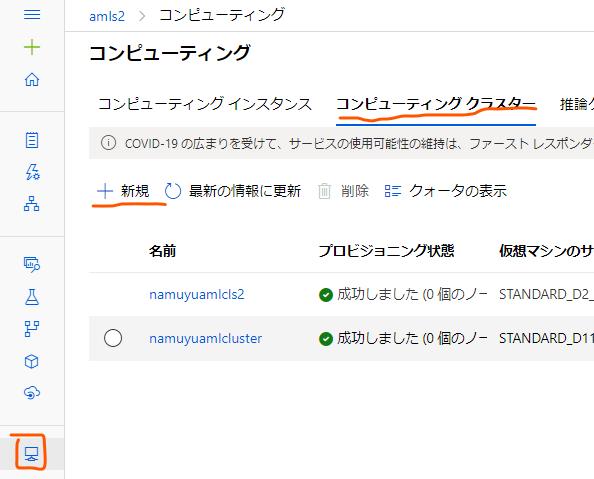
スタジオ画面に移動したらまずはモデルのトレーニングに使用するコンピューティングクラスターを作成します。
スタジオ画面の左端のアイコンの一覧から下から4つ目、コンピュータのモニターのようなアイコンをクリックし、開いた画面の中でタブを「コンピューティングクラスター」に移動します。
そこで「+新規」のボタンをクリックし、コンピューティングクラスターを新規作成します。
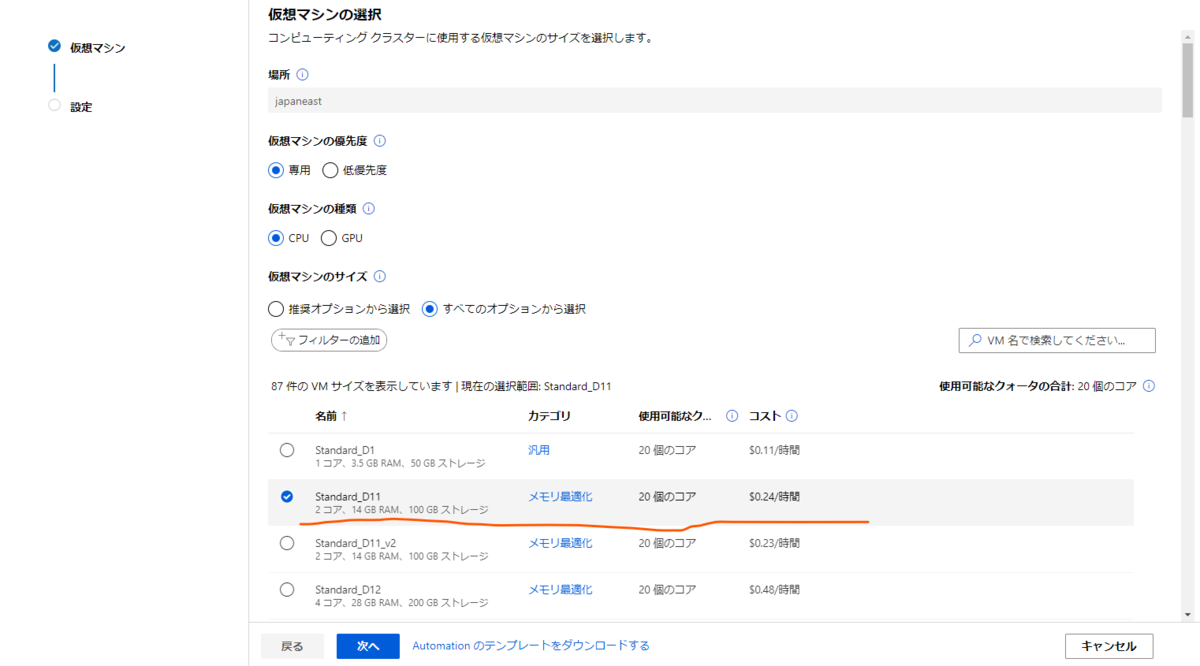
コンピューティングクラスターの設定画面ではコンピューティングクラスターの性能や名称を設定しておきます。
性能はStandard_D11程度が妥当かと思います。
後はコンピューティング名を設定し、「作成」ボタンを押してコンピューティングクラスターを作成します。

モデルのテンプレートを利用してトレーニングする
次はモデルを作成してトレーニングしていきます。
前回の記事ではこの部分を手作業で行いましたが、学習用のサンプルモデルはテンプレートにあるので、今回はそれを利用します。
スタジオ画面左端のアイコン一覧で「デザイナー」のアイコンをクリックし、デザイナーのトップ画面に移動します。
そして、その画面の上部に「Regression - Automobile Price Prediction (Basic)」というサンプルがあるので、これをクリックします。
これは自動車の価格を予測する回帰モデルで、メーカーやドアの数などといったその車の要素から価格を予測します。

サンプルをクリックすると前回の記事で作成したようなモデルトレーニングのパイプラインが自動生成されているので、さっそくモデルのトレーニングを行っていきます。
まずは、トレーニングを行うコンピューティング先を指定します。
パイプラインのデザイナー画面の右の方から、「コンピューティング先を選択」をクリックします。
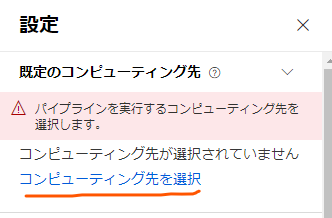
するとコンピューティング先のセットアップのモーダルが出てくるので、作成したコンピューティングインスタンスを選択し、「保存」をクリックします。
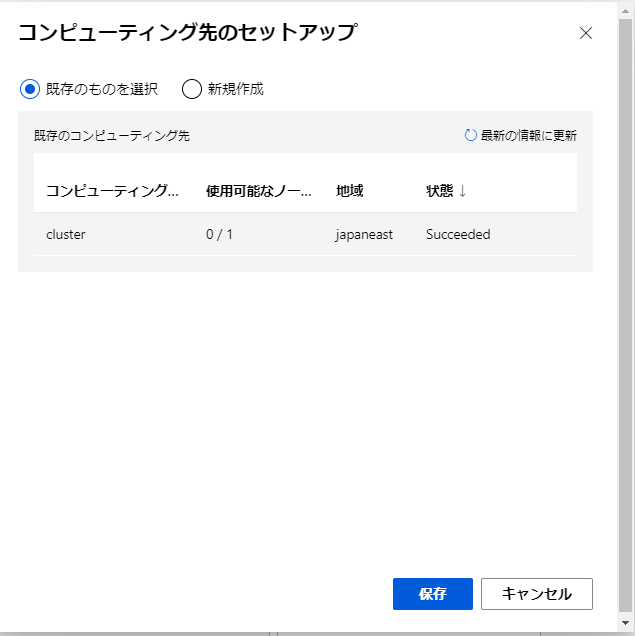
これでモデルのトレーニングを行うクラスターがセットアップできたので、それを使用してトレーニングを行っていきます。
デザイナー画面の上部に「送信」のボタンがあるのでこれをクリックします。

セットアップが面では実験は「新規作成」をクリックし、実験名を入力して「送信」ボタンをクリックして実験を開始します。
そこそこ時間がかかるのでしばらく待ちましょう。
ただ、最近はAzure上のVMのリソースがひっ迫しているのか、VMの割り当てに時間がかかりまくった挙句「VMが足りなくて割り当てられなかったよー」というようなメッセージが表示されることがあります。
Azure Machine LearningでのVMリソースは基本的に普段は割り当てず、トレーニングを行う時にだけ払い出すようにできます。(例えば、クラスター作成時に「最小クラスター数」を0にした場合とか)
その際、「よしトレーニングやるぞVM確保しなきゃ」となったタイミングでそのリージョンにVMの数が足りないとそれによってVMの確保に失敗することがあるためです。
特に自分の場合東日本リージョンで何度か試したのですが何度やってもVMが確保できなかったため、別のリージョンにAzure Machine Learningのリソースを作り直してこの先の作業をやり直したりしました。
このエラーが出たら、Azure Machine Learningのリソースの再作成からやり直す羽目になります。
リアルタイム推論パイプラインを作成して実行する
回帰モデルのトレーニングが完了するとデザイナー画面の上部に「推論パイプラインの作成」というドロップダウンメニューが出てくるのでこれをクリックして、「リアルタイム推論パイプライン」をクリックし、リアルタイム推論パイプラインを作成します。
これによって既存のデザイナーのパイプラインにいくらか要素が追加されたパイプラインが新たに生成されます。
新たに追加されたパイプラインでは、それまでのパイプラインの書くモジュールに加えて、「Web Service Input」と「Web Service Output」という要素が追加されています。
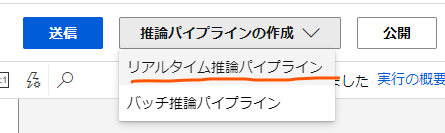
パイプラインが新たに生成されたら、こちらも同様に画面上部から「送信」をクリックしてモデルのトレーニングを行いましょう。
モデルのトレーニングを行っている間に次の工程である推論クラスターの作成を行います。
推論クラスターを作成する
推論クラスターは、回帰モデルをWebアプリとしてデプロイする先のAKSのkubernetesクラスターになります。
これを作成します。
再び、コンピューティングの画面に移動し、「推論クラスター」のタブを選択し、「作成」のボタンをクリックします。
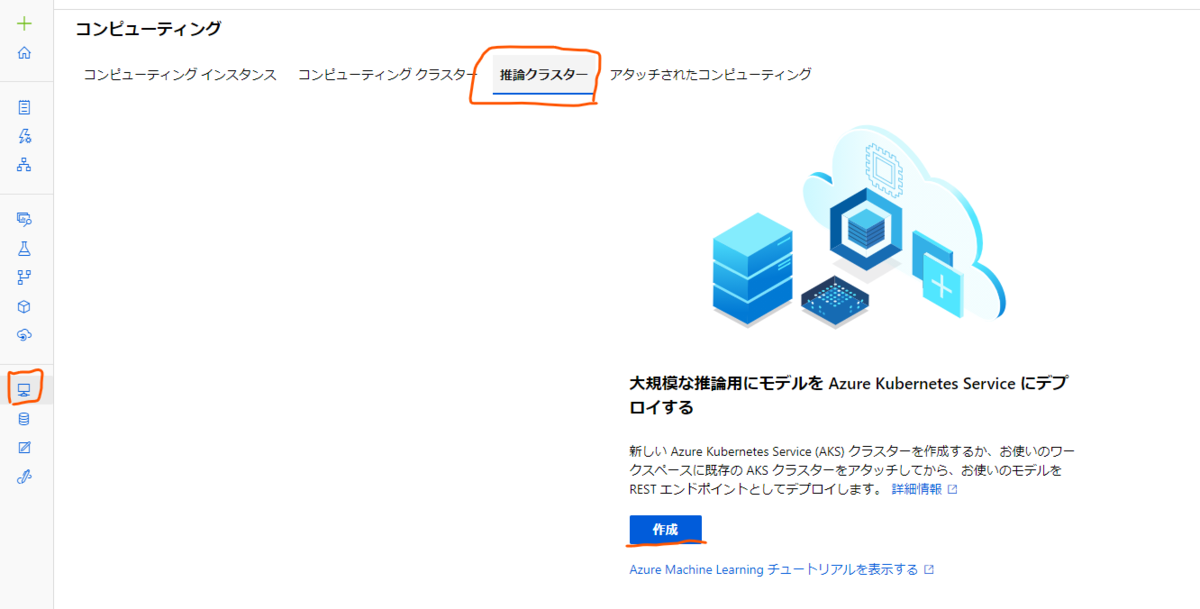
まずは作成するクラスターのVMサイズを選択しますが、安めのサイズを選択しておきます。
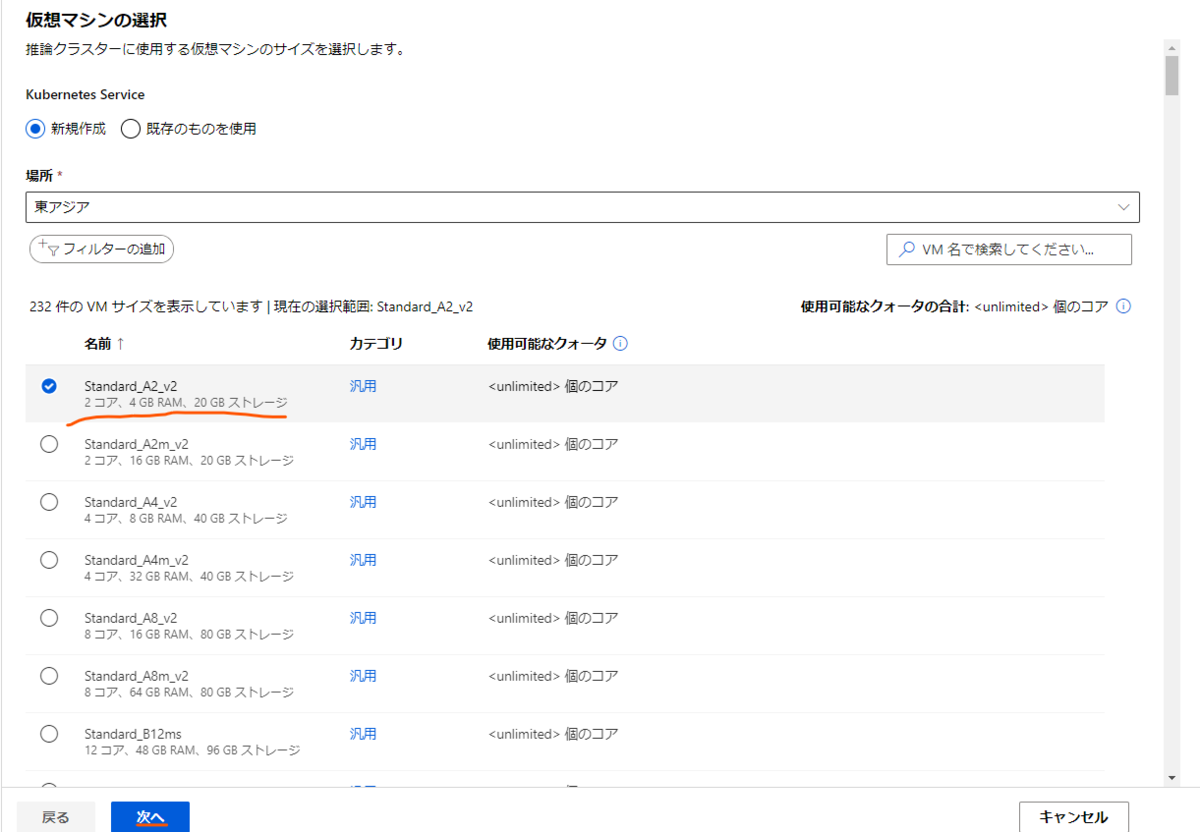
次の画面では分かりやすいコンピューティング名を設定し、クラスターを作成します。
推論クラスターにアプリをデプロイする
推論クラスターが作成でき、リアルタイム推論パイプラインのモデルトレーニングが完了したら、リアルタイム推論パイプラインの編集画面に戻ります。
画面の上部の「送信」ボタンの横に「デプロイ」ボタンが有効になっているかと思います。
これをクリックします。
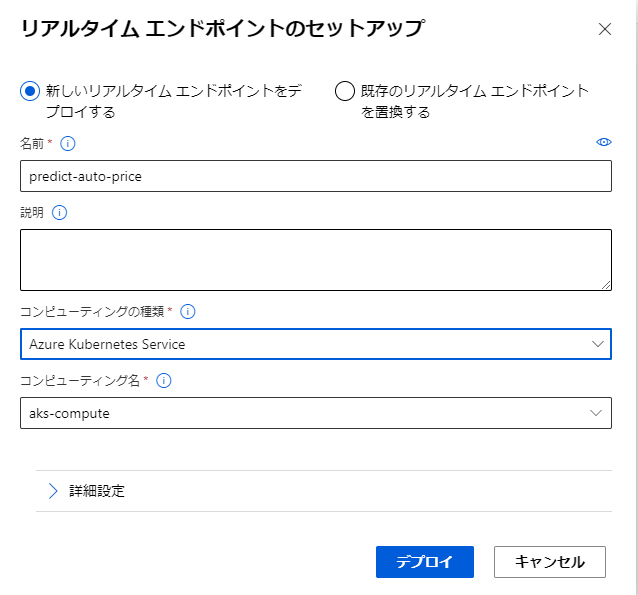
すると、「リアルタイムエンドポイントのセットアップ」というモーダルが出てくるので、回帰モデルをWebアプリとしてデプロイする準備をします。
分かりやすい名前を設定し、コンピューティングの種類としては「Azure Kubernetes Service」を選択します。
その下のコンピューティング名には先程作成した推論クラスターを選択し、「デプロイ」をクリックして回帰モデルをWebアプリとしてAKS上にデプロイします。
アプリをテストする
これでモデルがAKS上で利用できるようになったのですが、実際にそのモデルを試してみましょう。
今度は、スタジオ画面左は地のアイコン一覧から、「エンドポイント」をクリックします。
するとリアルタイムエンドポイントの一覧が表示されるので、先程作成した名前のエンドポイントを選択します。

エンドポイントの詳細画面が表示されますが、画面上部から「テスト」タブを選択します。
すると、作成した回帰モデルにリクエストする各種パラメータの入力フォームが出てくるので、ドアの数、メーカー名などを好みに設定して「テスト」ボタンを押します。
すると、画面右にテスト結果の出力が表示されます。
これを下の方までたどっていくと「Scored Labels」という値があるかと思います。
この値が、今回の回帰モデルで予測された「price」の値になります。
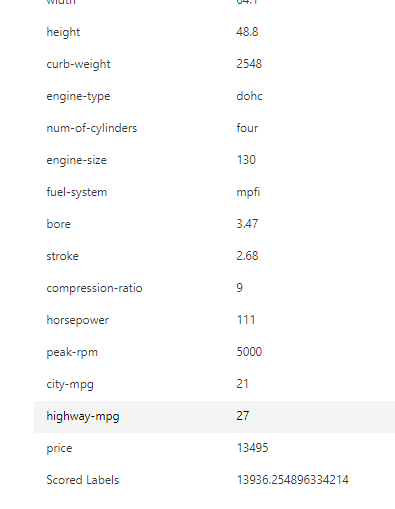
これにて後ろでテストが行われ、回帰モデルがWebアプリとしてAKS上にデプロイされていることが確認できました。
おわりに
今回はAzure Machine Learningで作成したモデルをWebアプリとしてAKS上にデプロイする方法を共有しました。
WebAPIとしてデプロイすることで他アプリからも利用しやすくなり、また、AKS上で独立したサービスとすることでモデルの更新などにも対応しやすくなります。
モデルをアプリ化して独立したアプリとするという考え方はAzure Machine Learning以外のプラットフォームでも使えそうな概念かと思うので、よっしゃこれから機械学習アプリを作るぞという際には心にとめておいていただけると幸いです。
参考
【小ネタ】Azure PipelineのMicrosoft-hostedなOSがubuntuのagentsでazcopyコマンドを使うときはazcopyのバージョンに気をつけるんよー
 この記事はcloud config tech blogにもマルチポストしています。
この記事はcloud config tech blogにもマルチポストしています。
はじめに
タイトルが長いですね。
あと何も知らない人には何を言ってるかわからないですね。
ここにたどり着いた方は多分下の方に書いてるエラー文とかで検索に引っかかった方かと思います。
今回はそういった方向けのお話になります。
結論から
Azure PipelineのMicrosoft-hostedなagentを使ってazcopyのv7にはなくてv10には含まれるコマンドを使おうとした場合、azcopyコマンドのエイリアスは azcopy10 でないとThe syntax of the command is incorrect. Unrecognized command or argument 'copy' といったエラーが発生します。
エラーの意味合いとしては「azcopyにcopyと続くコマンドはないよ~」というものです。
この例ではMicrosoft-hostedなUbuntu OSのagentで azcopy copy とコマンドを打ったのですが、その際に使われたazcopyのバージョンはv7で、それには azcopy copy のコマンドが含まれていなかったことが原因です。
azcopyのv10で追加されたコマンドである azcopy copy を使用しようとした場合、 `azcopy10 copy' で書き始めることでこの問題は解決できます。
もうちょっと詳しい話
これだけだと味気ないのでもう少し結論の話に肉付けします。
Microsoft-hostedのagentとは何かということとそれに最初からインストールされているソフトウェアのお話、あとその中のazcopyコマンドのお話です。
Microsoft-hostedなagentとは
Azure pipelineではパイプラインで処理を実行するためにAgentと呼ばれる、Azure上でホストされたVMを使用します。
このVMは、自分で設定したVMを使用する(Self-hosted agent)他、Microsoftによってあらかじめ設定されたVM(Microsoft-hosted agent)を使用することもできます。
Self-hosted agentにおいては、Pipelineでビルドを行う際に必要なソフトウェアをユーザーが決めてインストールすることになります。
この作業は手間でもあるのですが、代わりにインストールするソフトウェアやハードウェア性能をより細かく設定できるという利点でもあります。
これによって、例えばアプリビルド時にライセンスが必要なUnityを設定したGPUマシマシのハイエンドなVMを用意してUnityアプリを高速でデプロイするなんてこともできます。
一方で、Microsoft-hosted agentではビルドに使うことがある多くのソフトウェアのインストールや準備を既に行っているVMが利用できます。
これによって、特にインストールなどをしなくてもaz cliやdotnet コマンド等を使用することができ、ビルドやデプロイのためにソフトウェアのインストールの手間をかけずに済みます。
逆に最初からインストールされていないソフトウェアを使用する場合は、agentのVMはパイプラインの処理ごとに変更が初期化されるため、毎回インストールの処理をしなければなりません。
Microsoft-hosted agentsの中でもさらにWindows Server OSを利用したものやUbuntu、Mac OSをインストールしたVMを使用することができます。
これによって、ビルドに使用したいマシンのOSについてある程度選択することもできます。
一般的には最初から使用できるようになっていて、かつ最初から十分に設定が行われているMicrosoft-hostedなagentを使用することになるかと思います。
Microsoft-hostedなagentにインストールされているソフトウェアの話
Microsoft-hostedなagentには初めからビルドに使うソフトウェアが色々インストールされているため特にパイプライン内でソフトウェアのインストールをせずにaz cliやdotnetコマンドなどを使用できるというお話をしましたが、実際にどのようなソフトウェアがインストールされているかはこちらのドキュメントに纏められています。
それぞれのOSのLinkから、そのOSのagentにインストールされているソフトウェアの一覧を見ることができます。
例えば、基本的に全部のOSにaz cliやdotnetコマンドがインストールされているほか、Go、npm、gitなども全部のOSでインストールされています。
面白いものではRも使えるようです。
あと、UbuntuとWindows Server限定ですがDockerコマンドも利用できます。
よくやるのはGithubにコードをマージされたらDockerコマンドでコンテナ化してazコマンドでACRにデプロイとかですね。
ただしUbuntuのazcopyには注意
今回の記事の主題として注目してほしいのがこの中のUbuntuのagentにインストールされているazcopyの欄です。
Ubuntu OSのagentにはAzCopyのバージョン10.8と7.3がインストールされているのですが(2021年2月現在)、エイリアスがそれぞれ azcopy10 と azcopy になっています。
azcopy10 とコマンドを打つとazcopyのバージョン10.8が使用され、 azcopy とコマンドを打つとバージョン7.3が使用されます。
一方で他のOSのエージェントだとどれもazcopyのバージョン10.8のみ利用可能で、azcopyとコマンドを打つとバージョン10.8のazcopyが実行されます。
Ubuntuのagentでのみ、 azcopy のコマンドを打つとバージョン7.3のものが使用され、azocopyコマンドは認識されるもののバージョン10で追加されたコマンドが見つからず使用できないということが起きます。
気をつけましょう。
おわりに
最近行っていたパイプライン周りの作業でこのような問題に引っかかってエラーシュートに時間がかかったので「こんなおとがあるよー」という共有でした。
同じ問題で詰まった方の助けになれば幸いです。
参考
- Microsoft-hosted agents
- Ubuntu 20.04.2 LTS
Microsoft-hostedなagentのうちubuntu-20.04ベースのものにインストールされているソフトウェアの一覧です。
Azure DevOps PipelineのPowerShellで各種変数の取得方法チートシート

この記事はcloud.config tech blogにもマルチポストしています。
はじめに
みなさーん、パイプライン、組んでますか?
組んでたらどうというわけでもないのですが、最近パイプライン組み盛りのなむゆです。
Azure DevOps Pipelineではパイプラインを実行するためにyamlファイルを書きますが、そこでは様々な方法で設定した変数を利用できます。
特にpowershellでは設定した変数をフル活用して各種処理を行ったりするのですが、その設定した変数を使うときに毎回シグナルを忘れて調べる羽目になっていたのでチートシートを作った共有です。
PowerShell以外のタスクにおいても引数の取得はできますが、所によって取得のシグナルが異なっていたりするので、一番よく使う例、あと他のタスクでもたいてい同様になる例としてpowershellでのシグナルをまとめています。
各種変数の取得方法チートシート
| 変数の取得元 | 変数使用時のシグナル |
|---|---|
| パラメータ | ${{ parameters.パラメータ名 }} |
| variableで定義した変数 | $(変数名) または ${{ variables.変数名 }} |
| variable groupから取得する変数 | $(変数名) |
それぞれの変数と使いどころ
パラメータ(Runtime parameters)
パラメータはドキュメントでは「Runtime parameters」とも呼ばれ、パイプラインの実行ごとに引数として渡してやるのが特徴です。
それにより、パイプラインの実行ごとに値を切り替えることができるのでパイプラインの実行ごとに別の値を設定してやることが可能です。
yaml内では、一番上の階層にそれぞれ変数の名前、表示名、型、オプションでデフォルト値を設定して指定します。
例:
parameters:
- name: "sampleParam"
type: string
displayName: "SampleParameter"
使用時は、 $ と波かっこ二つで囲い、 parameters.の後に変数名を入れて使います。
例:
${{ parameters.sampleParam }}
variable
variableは、yaml内で設定できる一般的な固定値です。
主に同じ固定値を何度も使いまわすときに使っています。
固定値の値が変更になった時の修正範囲を少なくできます。
ドキュメントにあるように、root、stage、jobのスコープに対して変数を設定することもでき、全体に対して設定すると変数名が被るような場合にも適用範囲を分けて実行することができます。
また、もし変数名が被った場合は、rootよりstage、stageよりjobの変数の値が優先されます。
スコープが狭いものほど優先して適用されるあたりcssと若干似ている用にも感じますね。
例(rootに設定する場合):
variables:
- name: SAMPLE_VARIABLE_VALUE
value: sample variable value
使用時は、 $ とかっこで変数名を囲むか $ と波かっこで囲んでvariables.の形で書く方法が一般的です。
違いは変数の値が処理されるタイミングのようです。
テンプレートを使用しているか、conditionを使用しているかといった場合によって使い分けます。
variable group
variable groupは使用する変数の値をあらかじめ設定して保持しておく仕組みです。
これを使用することでparameter程ではないけれども使用する値が時々変更されるような場合や、yamlファイルの中には直接書き込みたくないシークレットの値を扱うことができます。
個別の値の設定の方法はドキュメントにあるので今回は省略します。
以下はパイプラインyamlでの使用例です。
variableと同様にvariablesに書きますが、- group として設定してやる必要があります。
例:
variables: - group: SAMPLE_VARIABLE_GROUP
これで、 SAMPLE_VARIABLE_GROUP のvariable groupから値が読み出されるようになりました。
個別のvariableの名前を宣言する必要はなく、これでこのvariable groupの中の変数が読み出せるようになります。
以下の例では、 SAMPLE_VARIABLE_GROUPのvariable group内にSAMPLE_VARIABLE_GROUP_VALUE という名前の変数が設定されていると仮定した例です。
例:
$(SAMPLE_VARIABLE_GROUP_VALUE)
なお、variable groupの値についてはpowershell内では $() の書き方のみ使用できるようです。
おわりに
今回はazure pipelineで設定する変数のpowershell上での取得方法のチートシートを共有しました。
パイプラインを作成する際にはたいてい何かしら変数を使って処理を出し分けたい要件があると思いますが、その際に役に立てば幸いです。
参考
久々に機械学習に触りたくなって。Azure Machine Learningで回帰モデルを作る・後編

この記事はcloud.config tech blogにもマルチポストしています。
続きまして
この記事は前回の「久々に機械学習に触りたくなって。Azure Machine Learningで回帰モデルを作る・前編」から引き続いての後編になります。
今回は前回作った「データ投入」「前処理」の部分に続き、「モデルトレーニング」の部分を作っていきます。
モデルのトレーニングを行う
まずは回帰モデルをトレーニングする部分のパイプラインを作成します。
「Normalize Data」の下に続けて画像のようにモジュールを探してきて配置します。配置したら、矢印をつなぎ合わせます。
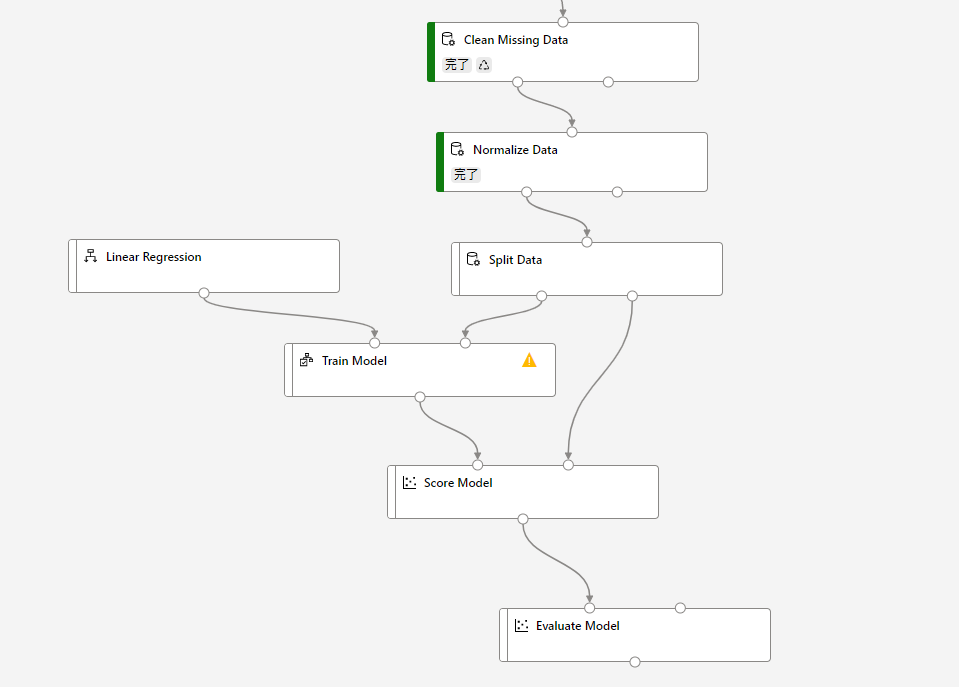
モジュールの配置と接続ができたら、それぞれの設定を行っていきます。
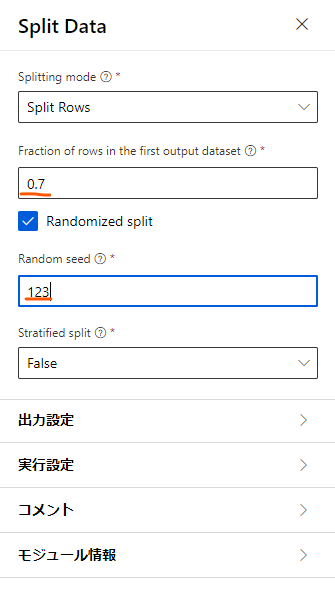
まずは「Split Data」の設定を開きます。
「Fraction of rows~」とある部分を0.7、Random seedはLearnと合わせて123にします。
「Fraction of rows~」は、下に伸びているパイプの左側に送るデータと右側に送るデータを分ける割合になります。
回帰モデルを作るのにあたって、モデルをトレーニングするのに使うデータとそのデータの評価をするのに使うデータを分けるために設定しています。
「Random seed」は、その割合でランダムに振り分けるときに使うシード値です。
続いて、「Train model」を設定します。
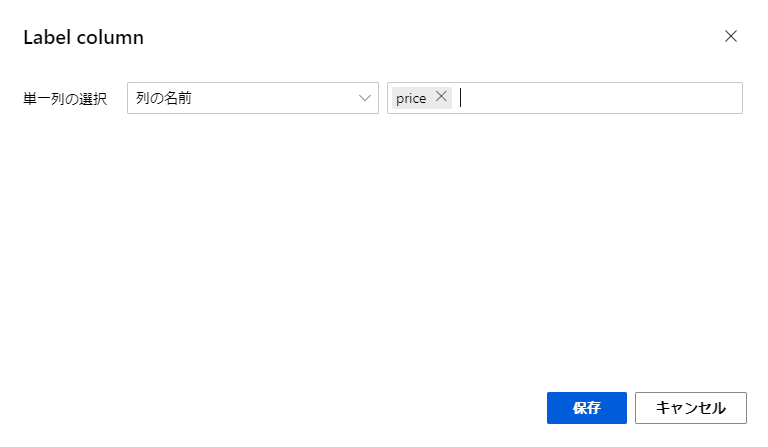
ここでは回帰モデルで予測する対象の値を決めます。
今回の分析では、車の各種情報から自動車の価格を予測しようとしているので、「列の編集」ボタンから、予測の対象である価格を選択しておきます。
これでパイプラインの設定は完了です。
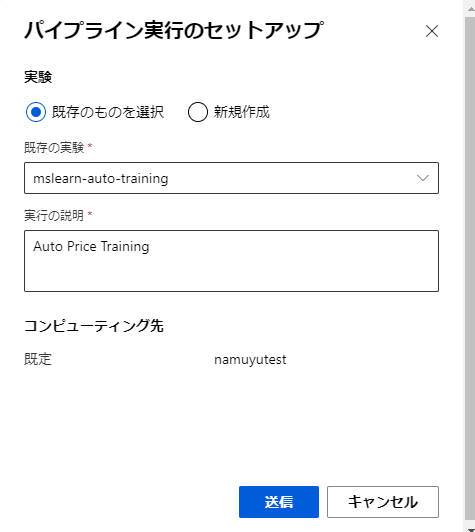
前回と同様にデザイナー画面上部の「送信」ボタンを押してモデルのパイプラインを実行します。
今回は、前回正規化まで行った実験があるので、それを選択します。
これによって、処理を途中まで行った結果を用いてそれ以降の処理を行うことができます。
「送信」ボタンを押して処理を実行します。
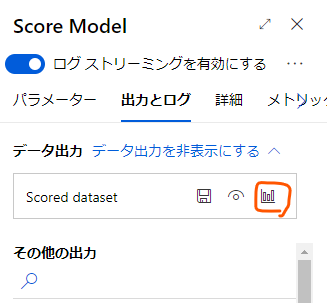
しばらくして処理がすべて完了したら結果を見てみましょう。
「Score Model」の「出力とログ」タブを開き、「Scored dataset」から視覚化のアイコンをクリックします。
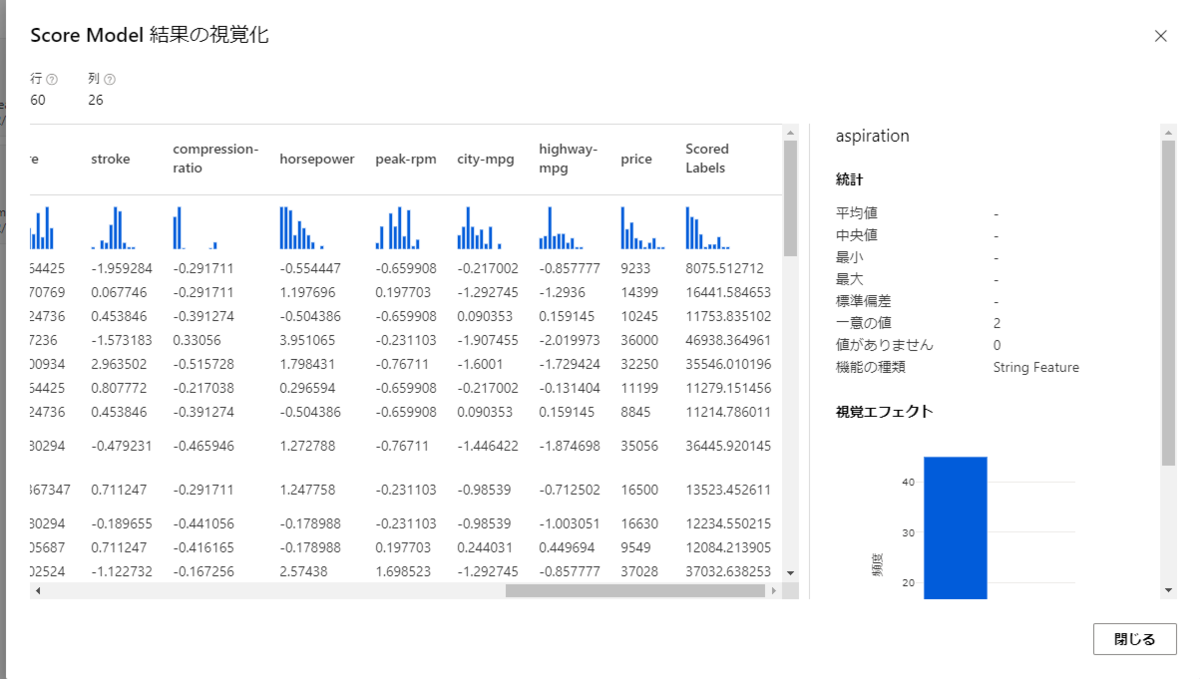
すると、このようなモデルのスコア付の結果が出力しています。
特に注目したいのが、「price」と「Scored Labels」の列です。
price はその車の実際の価格で、その隣のScored Labelsは今回トレーニングした回帰モデルを使って予測された価格です。
実際の価格より高かったり安かったりしますが、ある程度近い値が産出されているように見えるかと思います。
おわりに
今回は久々にAzure Machine Learningを利用して機械学習の実装を試してみました。
個人的には以前に書籍を読みながらいろいろ試したり学生時代からっきしだった数学にまた取り組んでみたりして打ち込んだ当時の情熱が思い起こされて何かしら懐かしい気分になりました。
Azure Machine Learningというサービスとしては触るたびに見た目が変わっていて、当時感じた技術やサービスの進歩の速さを今回も感じられました。
また定期的に触っていこうかと思います。
参考
久々に機械学習に触りたくなって。Azure Machine Learningで回帰モデルを作る・前編
 この記事はcloud.config tech blogにもマルチポストしています。
この記事はcloud.config tech blogにもマルチポストしています。
はじめに
最近、再び機械学習熱が出てきたなむゆです。
AzureにはAzure Machine Learningという機械学習をローコードで行うサービスがあります。
これで久々に遊んでみようと思ったのですが、いつも頼りにしている Microsoft Learningのハンズオンを試していて日本語翻訳周りでかなり混乱した部分があったので、そのあたりを補完しながらリソース作成→回帰モデル生成までの流れをまとめてみたいと思います。
ただ、纏めていたら分量と画像の量が多くなってきたので、今回は内容を前後編に分け、前半ではサンプルデータの正規化まで行います。
下準備
まずはAzure ポータルから「Azure Machine Learning」のサービスを検索し、リソースを作成します。
リソースの名前とリージョン名だけ妥当な名前を入力し、作成を行います。
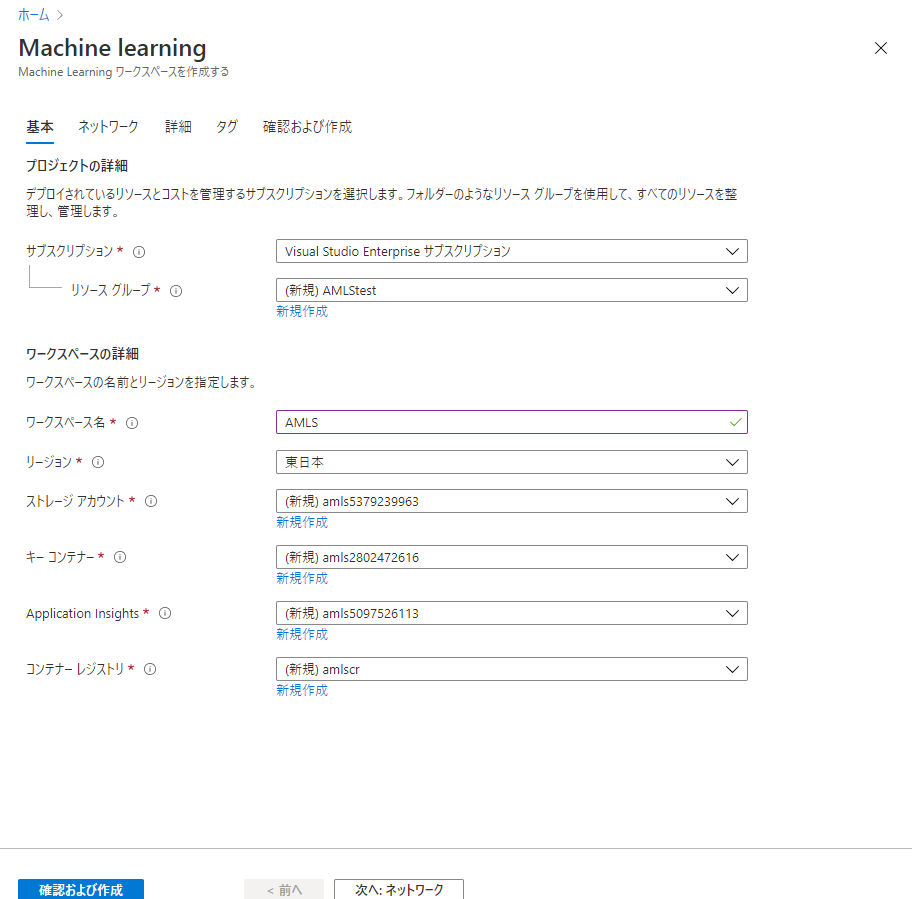
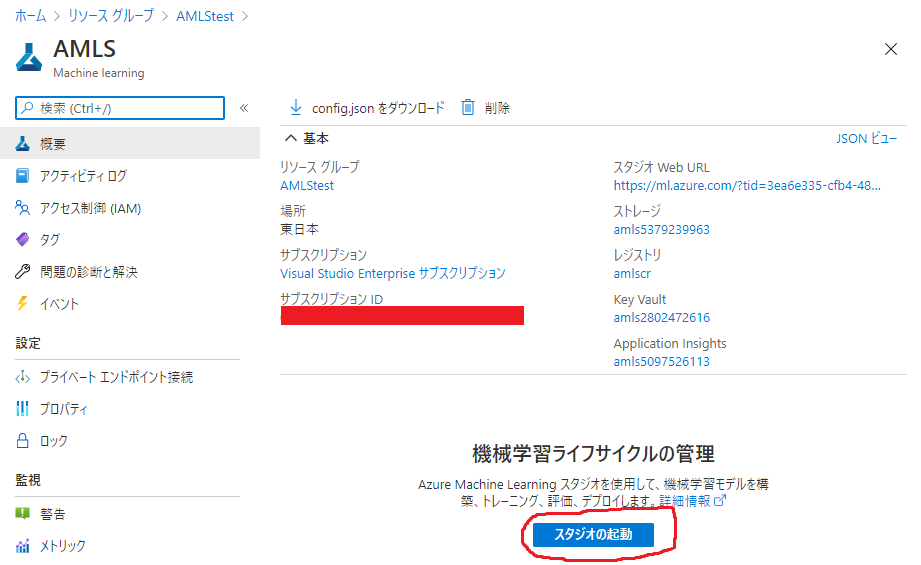
リソースが作成されたら、作成したAzure Machine Learningのリソースに移動し、「スタジオの起動」のボタンをクリックします。
すると、別タブでAzure Machine Learningの操作を行うスタジオのページが開きます。
Azure Machine Learningの機械学習関連のタスクは主にここで行われます。
次は機械学習モデルのトレーニングに必要な「コンピューティングクラスター」を作成します。
Machine learningスタジオのホーム画面の左下の方にある「コンピューティング」ボタンを押します。
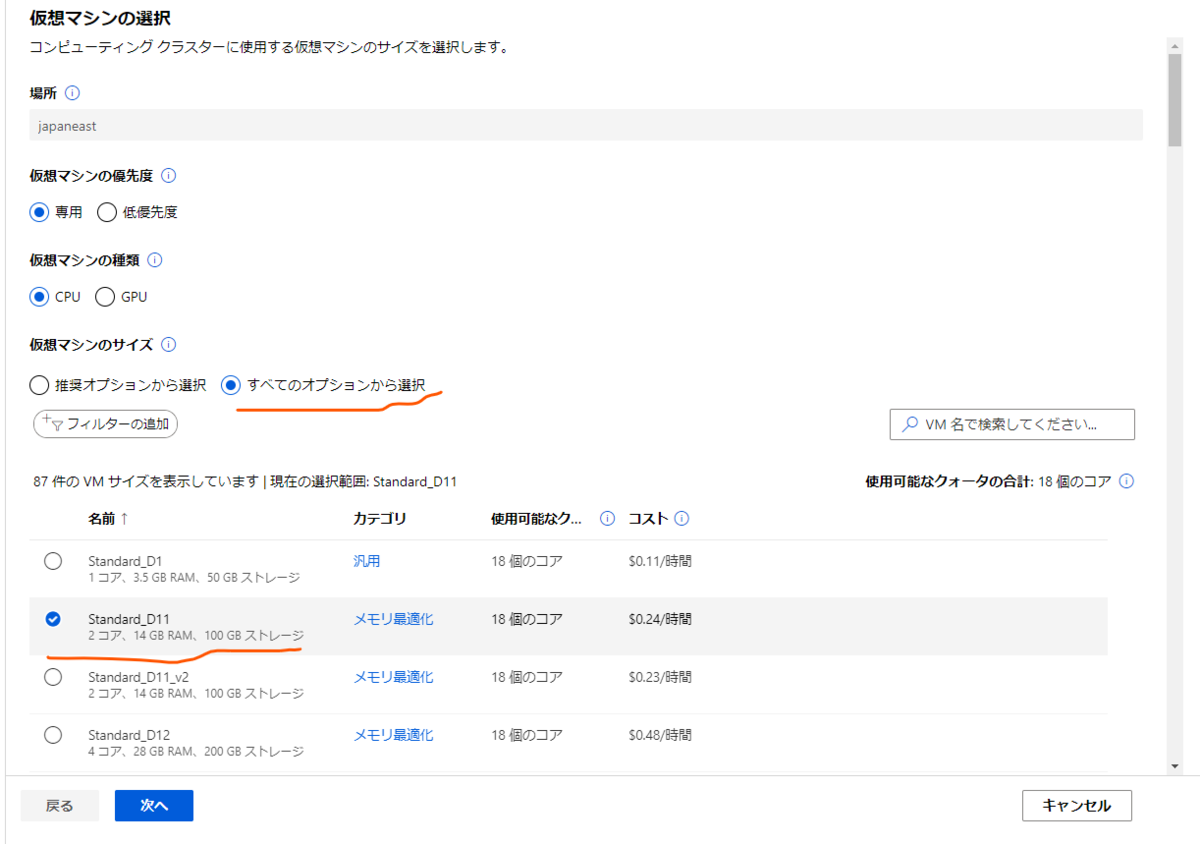
コンピューティングのページのタブを「コンピューティングクラスター」に切り替えます。
ここには作成したのコンピューティングクラスターの一覧が表示されますが現状は存在しないので「新規」ボタンから新規作成を行います。

設定内容としてははLearnで解説されているとおり仮想マシンに「Standard_D11_v2」を選択したいのですが、初期状態では仮想マシンの選択肢にそのオプションが表示されていません。
なので、「仮想マシンのサイズ」の欄の「全てのオプションから選択」のラジオボタンを選択状態にしてそのオプションを表示させ、選択しておきます。
設定したら「次へ」ボタンを押します。
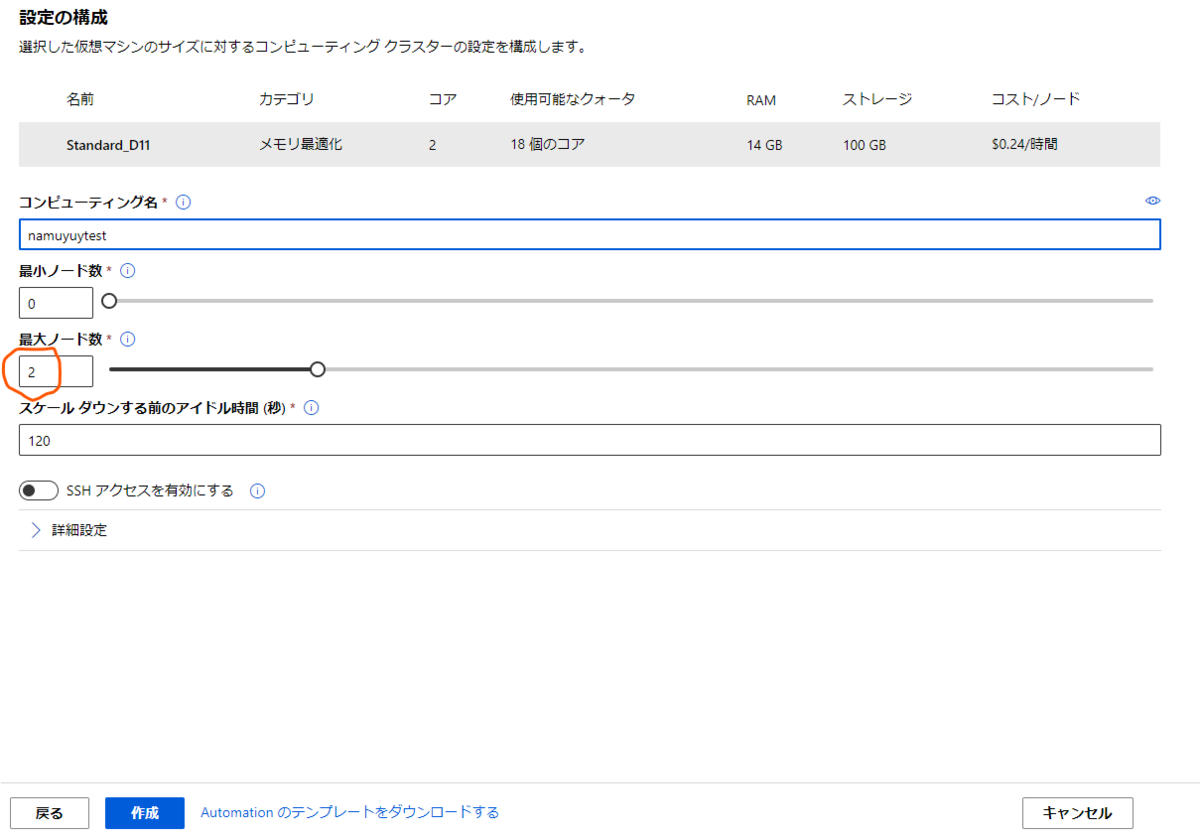
続いてクラスターのコンピューティング名などを設定します。
ここもLearnに合わせて最大ノード数を2に設定します。
コンピューティング名は覚えられるもので設定しましょう。自分の場合は「namuyutest」としています。
設定できれば「作成」ボタンを押してクラスターの作成を開始します。
これで必要な下準備は完了です。続いて実際にモデルを作成していきましょう。
データの前処理を行う
今回はオーソドックスに回帰モデルを作っていくのですが、一般的に機械学習を行う時の流れとして「データを取ってくる」→「データの前処理を行う」→「モデルのトレーニングを行う」という手順を踏みます。
この処理をそれぞれ一つの塊として、モデル作成の手順を一続きにしてつなぎ合わせたものを「パイプライン」と呼びます。
Azure Machine Learningで機械学習を行う方法の一つとして、そのパイプラインを「デザイナー」という機能を使って行うものがあり、今回はそれを利用します。
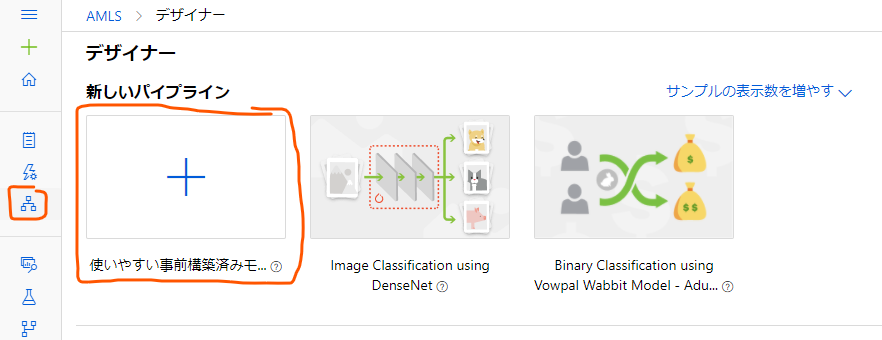
まずはホーム画面から、再び左の法のアイコン一覧のうち今度は上の方の「デザイナー」のボタンをクリックします。
すると、これまでデザインしたパイプラインの一覧の画面に移るのですが今回はまだパイプラインを作成していないので上の方のプラスボタンを押して新規作成します。
デザイナーの画面にやってきました。
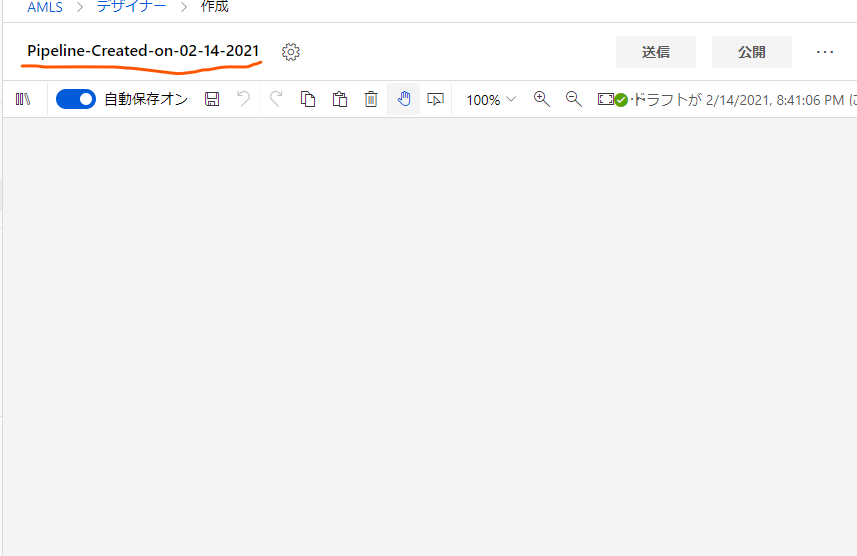
ここでまず行うのは、Learningと合わせてパイプラインの名称を変えることです。
現在のパイプラインの名称をクリックすると名前を変更できるので、「Auto Price Training」に置き換えておきます。適当にどこか別のところをクリックすると自動でセーブされます。
次に、その名前の横の歯車ボタンから、パイプラインの設定画面に入ります。
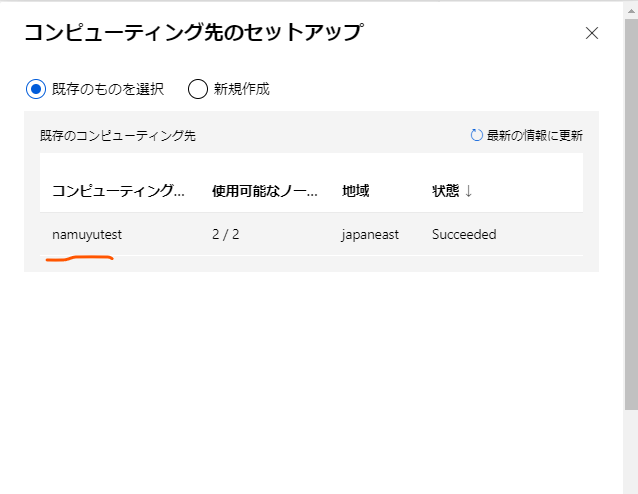
ここで、このパイプラインがモデルのトレーニングに使用するコンピューティング先(コンピューティングクラスター)を選択します。
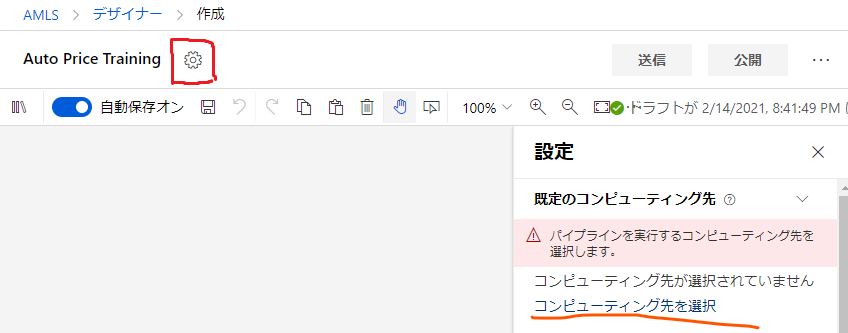
先程作成したコンピューティングクラスターを選択して確認ボタンを押します。
ちなみにその確認ボタンはモーダルの中の画面外の下の方にあるのでスクロールして探してください。
間の空白は一体。
設定を終えたら、パイプラインのデザインを行っていきます。
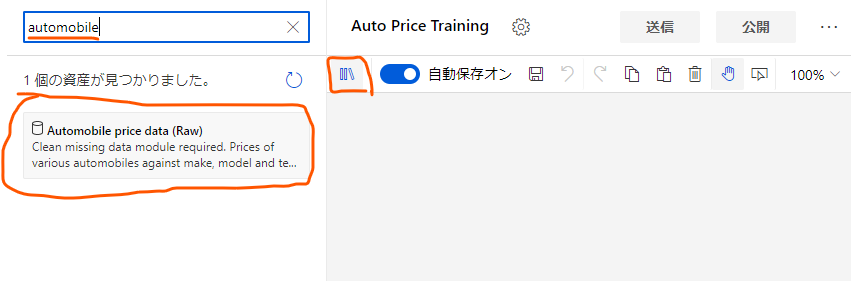
まずは、「データを取ってくる」の部分を作ります。デザイン画面右上の本棚のようなボタンを押し、出てくる検索窓に「automobile」あたりの文字を入力し、「Automobile price data (Raw)」を探します。
これが今回使用するサンプルデータです。
見つけられたら、これをデザイン画面内にドラッグアンドドロップします。
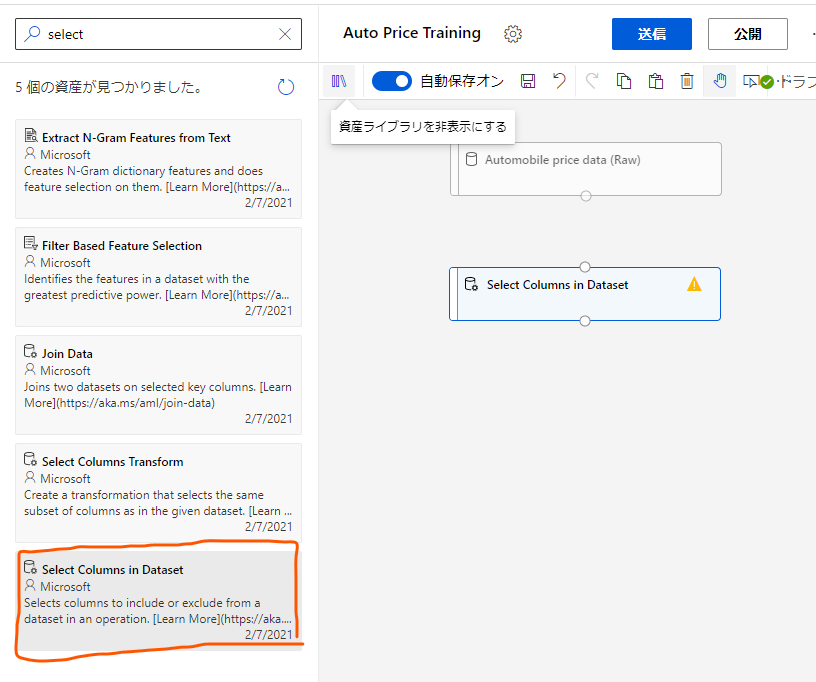
次はこのデータに前処理をかける部分を作成していきます。
再び本棚のアイコンをクリックし、今度は「Select Columns in Dataset」をドラッグアンドドロップします。
これはこのモジュールにやってきたデータから必要な列だけを選択する部分になります。
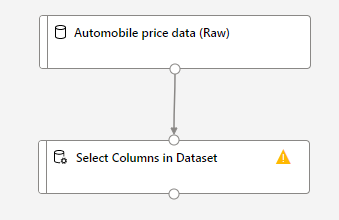
ドラッグアンドドロップ出来たら、これまで持ってきたモジュールをつなぎ合わせます。「Automobile price data (Raw)」の下の〇から「Select Columns in Dataset」の上の〇までドラッグします。
これによって、生のデータから列を選択することができるようになります。
次はその列選択の設定を行います。
列選択のモジュールをクリックし、右に出てくる設定画面から「列の編集」をクリックします。
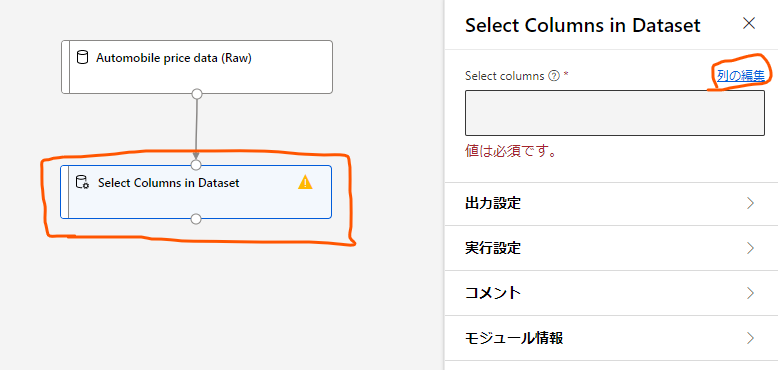
すると、このモジュールにやってくるデータの中のどの列を使用するかを選べます。
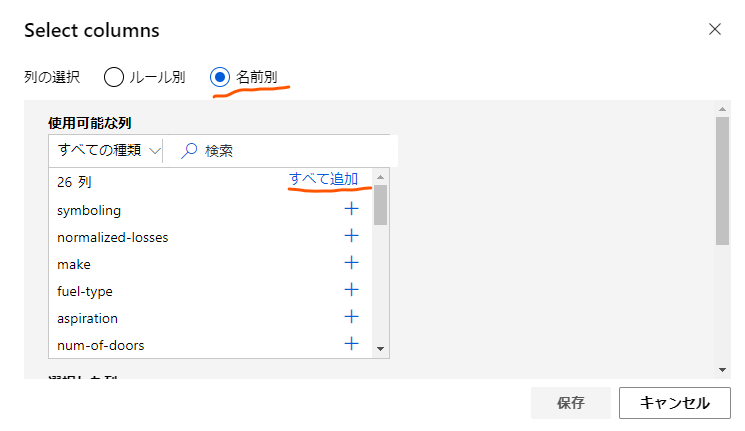
ここでは「名前別」のラジオボタンをクリックし、使用する列を選択します。
今回は「normalized-losses」以外の列を全部使用するので、列を全部追加した後で「normalized-losses」だけを削除する形で設定しました。
設定ができたら、「保存」ボタンをクリックして閉じます。
次は、「Clean Missing Data」と「Normalize Data」のモジュールを同じく本棚のメニューから探して持ってきて、画像のようにつなぎ合わせます。
これらは、それぞれデータの入っていない列のあるデータの削除を行ったり、データの正規化(それぞれのデータの値が取る値の範囲を扱い範囲に収まるよう変形する)を行ったりするのに使います。
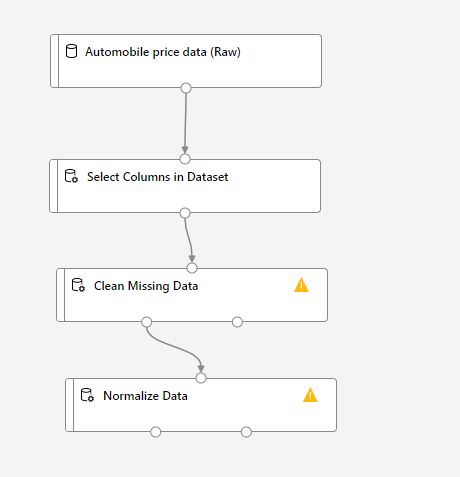
これらの設定を行っていきましょう。
まずは「Clean Missing Data」の設定から始めます。
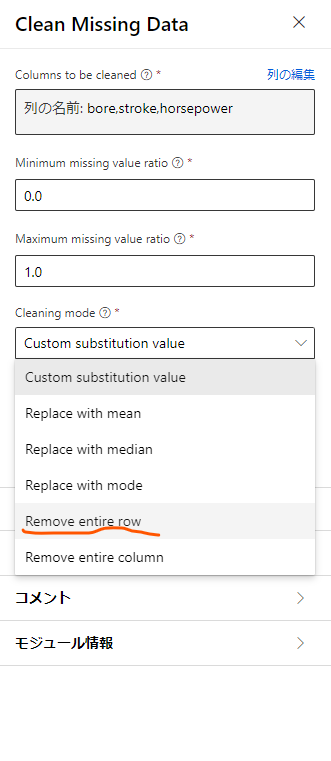
ここでは、特定の列に足りないデータがある際の動作を設定するのですが、まずは「列の選択」をクリックして足りないデータがあるかチェックする列を指定します。
今回は「bore」「stroke」「horseposer」の3つを設定して保存します。
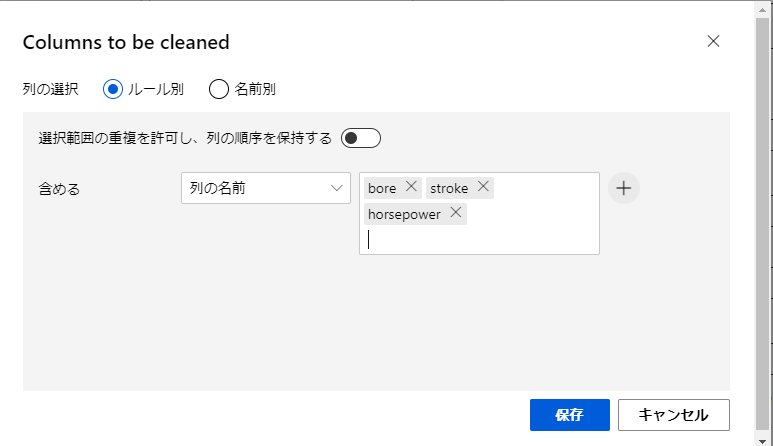
続いて、設定画面の下の方の「Cleaning mode」から、先程選択した列の値が存在しなかった場合の振る舞いを設定します。
今回は、それらの値が存在しなかった場合はそのデータがある行を丸々サンプルから排除することにするため、「Romove entire row」を選択します。
次に「Normalize Data」をクリックしてデータの正規化の設定を行います。
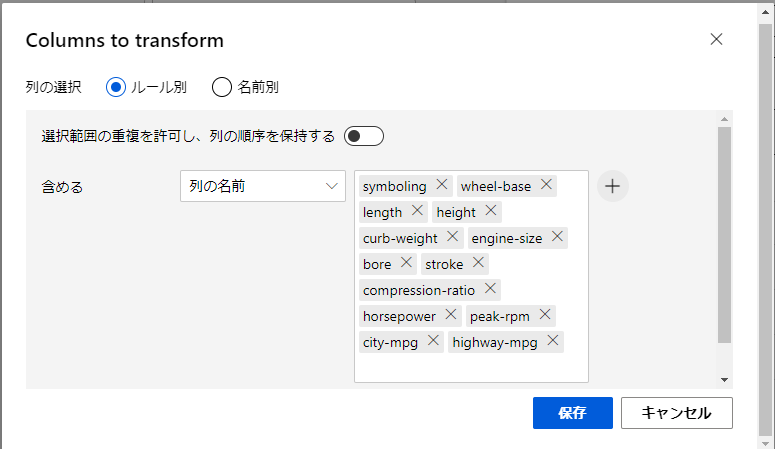
今回は、正規化の処理を行う列を選択するため、再び「列の選択」をクリックして設定モーダルを開きます。
ここでは、以下の画像に示している列の名前をルールに追加しておきます。
これによって、追加した名前の列のデータに対して正規化を書けることができます。設定できたら保存ボタンを押して戻ります。
ここまででサンプルデータの前処理のパイプラインを組むことができたので、これを実行してみましょう。
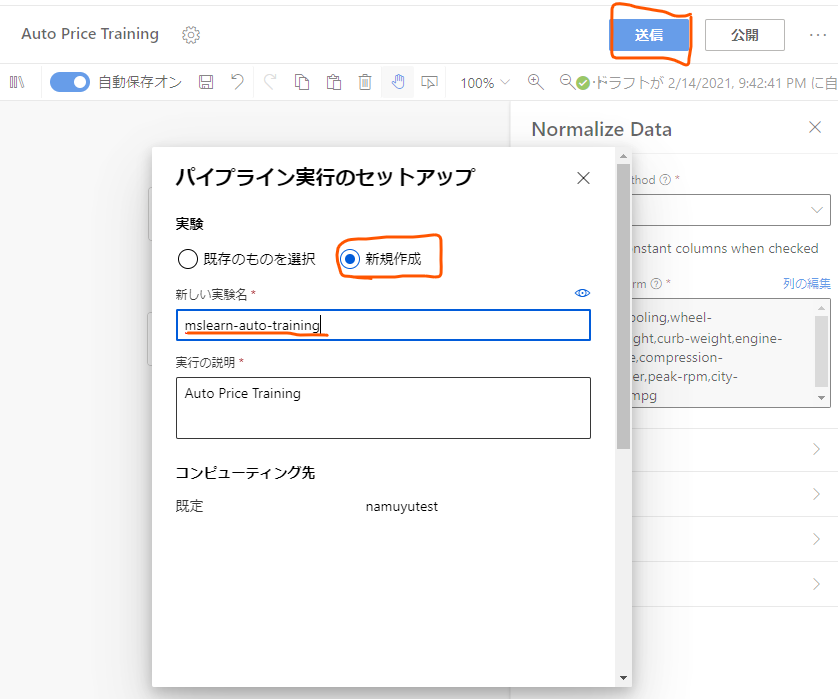
デザイナー画面上部の「送信」ボタンを押し、パイプライン実行のセットアップのモーダルを呼び出します。
新しい実行を行うので、「新規作成」のラジオボタンを選択し、新しい実験名として「mslearn-auto-training」を入力します。
設定ができたら下部の「送信」ボタンを押してこのパイプラインの処理をコンピューティングクラスターに送信します。
これで実験が始まるのでしばらく待ちましょう。
実験が進むと各モジュールの横に「完了」と表示され、全部のモジュールの処理が完了すればパイプライン全体の処理が完了となります。
処理の完了したモジュールは、その処理の終了時点での出力を確認することができます。
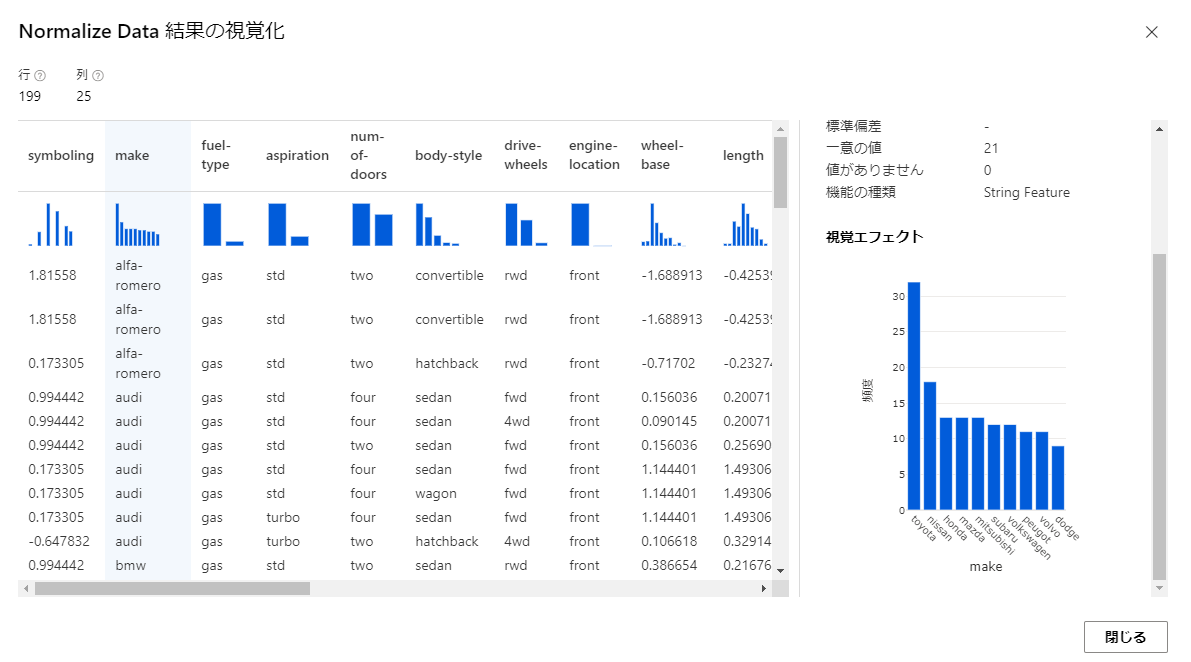
例えば、「Normalize Data」の出力を確認してみます。
Normalize Dataのモジュールを開き、「出力とログ」のタブを開きます。
上の方の「データ出力」の欄の「Transformed dataset」の棒グラフのアイコンをクリックすると出力されたデータが確認できます。
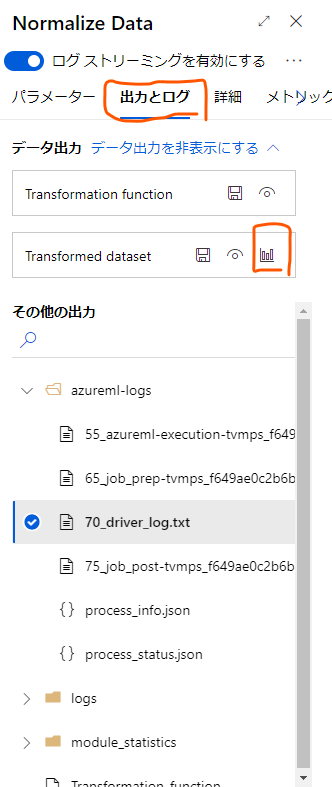
ここで各種データの値と、列ごとに集計された棒グラフが確認できます。
棒グラフからはデータの全体的な分布を把握することもできます。
この図とパイプラインの視点になる生データのモジュールの出力を見比べると前処理として削除されたデータや列があったり、正規化されてデータの値が大体-1から1の間に変換されている列があることが分かるはずです。
おわりに
今回はAzure Machine Learningのデザイナーを使用して機械学習のパイプラインをデータの正規化をするところまで作成しました。
Learnを見ながらやると途中で表示内容が違っていて詰まることが多かったので、その部分が補完できているとうれしいです。
続きはまた完成し次第リンクを張ろうと思います。