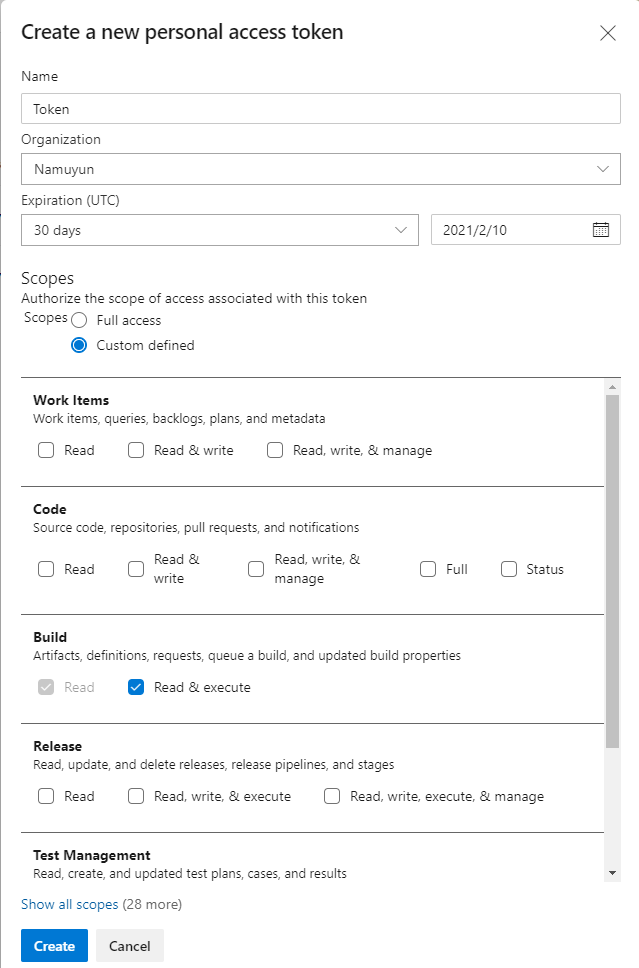
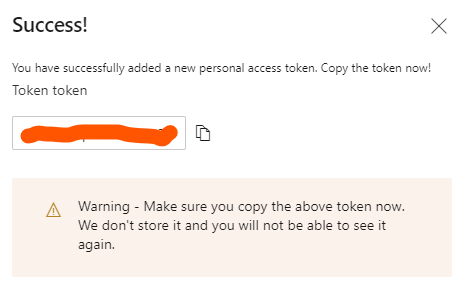
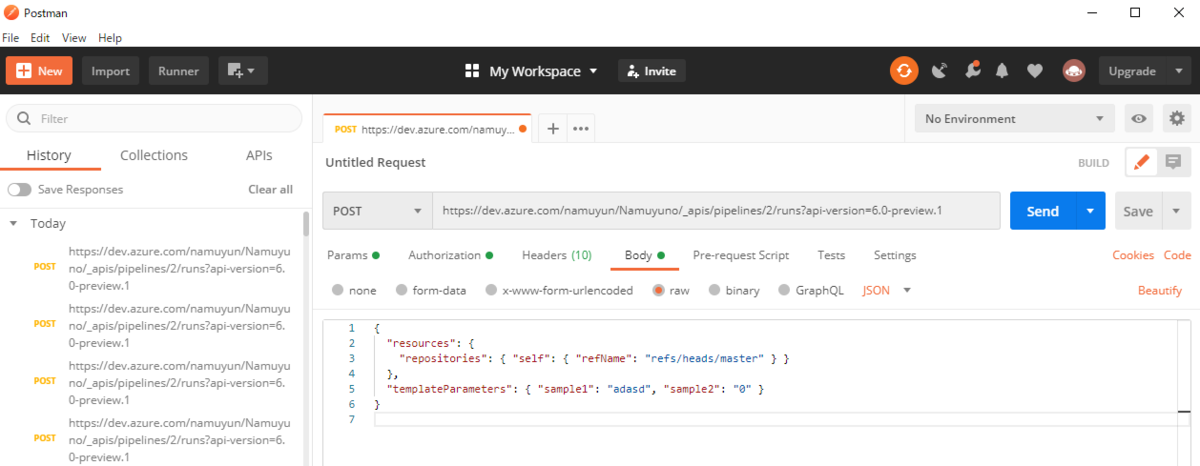
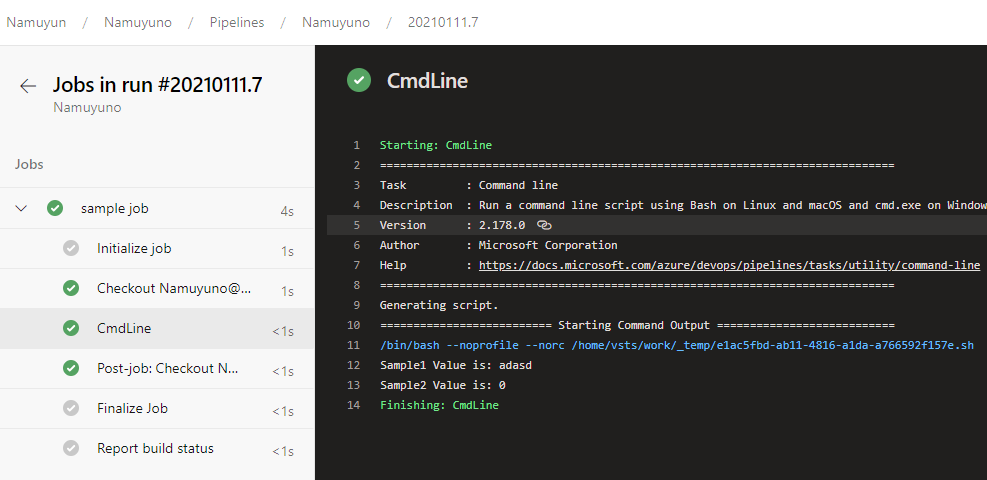
この記事は後ほどcloud.configのtechblogにマルチポストします。
この記事は後ほどcloud.configのtechblogにマルチポストします。
はじめに
最近Kubernetesの勉強をしているなむゆです。
特にAKSについて勉強するために自前のサブスクリプションにリソースを立ててみたりもするのですが、AKSって今のところ一番安くてひと月4000円からかかるんですよね。
数日間リソースを立てっぱなしにした日にはすぐに1000円以上課金されたりしてしまいます。
というか今月そんな調子です。
できれば一定金額以上使ったらそれ以上使えないようにしたいのですがそういう方法が見つけられなかったので、次善策として「今月の課金額が〇〇円を超えたよ~」というアラートを設定するようにしているので今回はその方法の共有です。
課金アラートの設定方法
まずはAzureのポータル画面の上部の検索欄で「サブスクリプション」を入力して検索し、選択します。
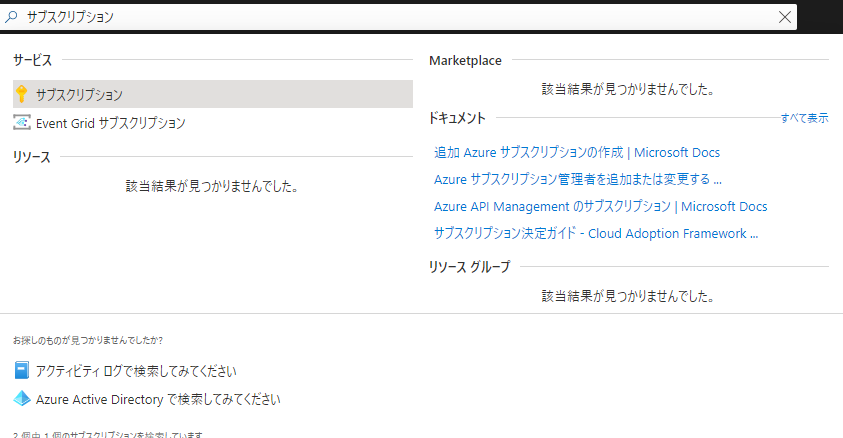 するとサブスクリプションの一覧画面に移るので、自分が今使っているサブスクリプションを選択します。
するとサブスクリプションの一覧画面に移るので、自分が今使っているサブスクリプションを選択します。
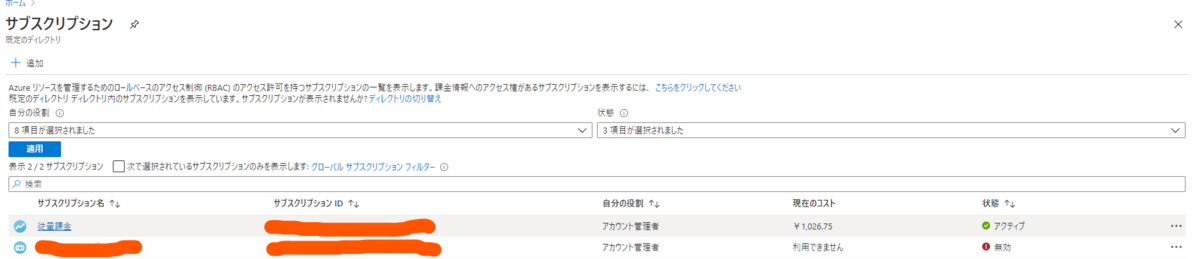 するとそのサブスクリプションの情報が表示されるので、左のメニューの一覧から「コストのアラート」を選択します。
するとそのサブスクリプションの情報が表示されるので、左のメニューの一覧から「コストのアラート」を選択します。
ちなみに、すぐ上の「コスト分析」をクリックすると現在の課金額が確認できますよ。
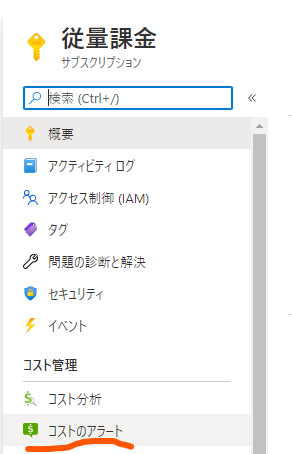 課金額が一定を越した際にアラートを設定するには画面上部の「追加」をクリックします。
課金額が一定を越した際にアラートを設定するには画面上部の「追加」をクリックします。
 すると、予算の作成の画面に移動します。
すると、予算の作成の画面に移動します。
名前と予算額を設定するのですが、ここでいう予算額が「だいたい毎月使うのはこのくらい」という値で、あとでアラートを発する課金額の閾値のベースの値になります。
設定したら「次へ」をクリックします。
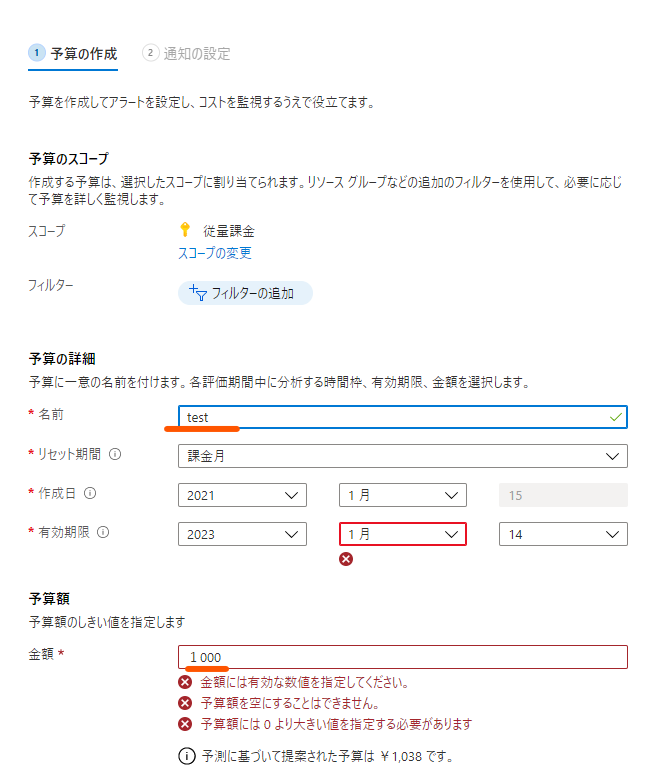 次は、アラートを発する条件とアラートを送信するメールアドレスを設定します。
次は、アラートを発する条件とアラートを送信するメールアドレスを設定します。
予算額をベースに、予算の何%の課金がされたタイミングでアラートを送るかを設定できます。
予算額に達したタイミングでメールを送りたい場合は100%でも問題ないですが、念のため200%とかでも送るようにした方がいいかもです。
予算の100%を超えたくらいだったら大抵無視するし予算の2倍も使ってますよってアラートが来たら「さすがにやべぇ」って気分になるじゃないですか。
余談はさておき、他に送信するメールの言語も設定して、「作成」をクリックします。
 これで設定は完了です!
これで設定は完了です!
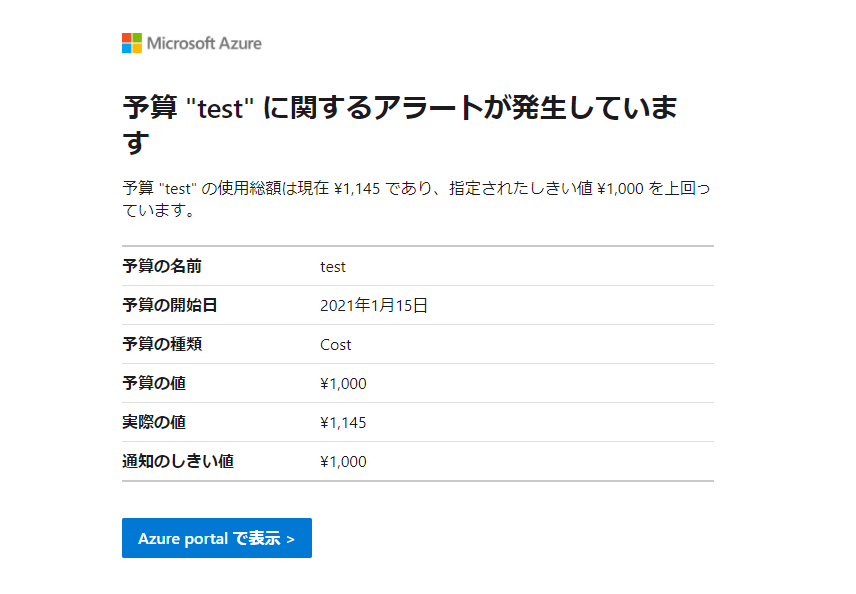
課金額が指定した閾値を越すとこのようなメールが届きます。やべぇ。AKS止めなきゃ。というかローカルでminikube立ててもいいな・・・
おわりに
今回はAzureの課金額でアラートを発する方法を共有しました。
課金額周りで色々調べたり予算設定したりアラートを発する機能はサブスクリプション周りに集まっていて、個人で使う時以外でも組織上の目的でも色々使うことになると思います。
参考に書いているドキュメントあたりが取っ掛かりになるかと思うので、その周りから調べてみると目的に合うものが見つかるかもしれません。
今回も読んでいただきありがとうございました。
お役に立てれば幸いです。