 この記事はcloud.config tech blogにもマルチポストしています。
この記事はcloud.config tech blogにもマルチポストしています。
結論
今回は結論から書きます。「SQLでいうところのアレ、KQLだとどんな感じだったっけ」という人はココだけ読めば解決です。
|SQL|KQL|
|---|---|
|SELECT | project|
|FROM句 | 一番最初の行にテーブル名を書くだけ|
|WHERE | where|
|LIKE '%[検索文字]%' | contains "[検索文字]"|
|GROUP BY | summarize|
|ORDER BY | sort by|
|LIMIT(またはOFFSET~FETCH) | take|
|COUNT | count|
※他にも思い出したものがあれば順次追加していきます
また、書いている途中で見つけたのですがもう少し広い範囲での対応表はMicrosoftによってこちらに元々用意されているようですのでこちらも見てみてください。
クエリ例
StormEvents | project State, StartTime, EpisodeId, EventType, InjuriesDirect, Source | where Source contains "new" | sort by StartTime | take 100
基本的な書き方として、偉業目にテーブル名を書いて2行目以降は「|」を挟んで書きます。
KQLとは
KQLは、SQLでいうところのCRUDの動作のうちRead動作だけを行えるちょっと特殊な書き方をするクエリ言語です。「Kusto Query Language」の略がKQLです。
主な使用場面としては、Azure Log Analyticsのようなログを蓄積するリソースにおいて蓄積されたログデータを検索、表示させる際に使用します。Log Analytics他にも使う場面はあるのかもしれませんが網羅的に把握はできてないです・・・。
ログのような大量の蓄積されたデータから、効率よく、欲しい形で簡単にデータを読み出すためのクエリ言語がKQLであるという形です。読み取りしかできないというのも使用用途がログの検索であるというところからきているようです。
他にも、今回はスコープから外れるので紹介しませんでしたが「render」というキーワードを使用してログから簡単にグラフを出力する機能もあります。
例えば以下のようなクエリを書くだけで簡単にタイムチャート図が出力されます。
StormEvents | summarize count() by d = bin(StartTime, 30d) | render timechart
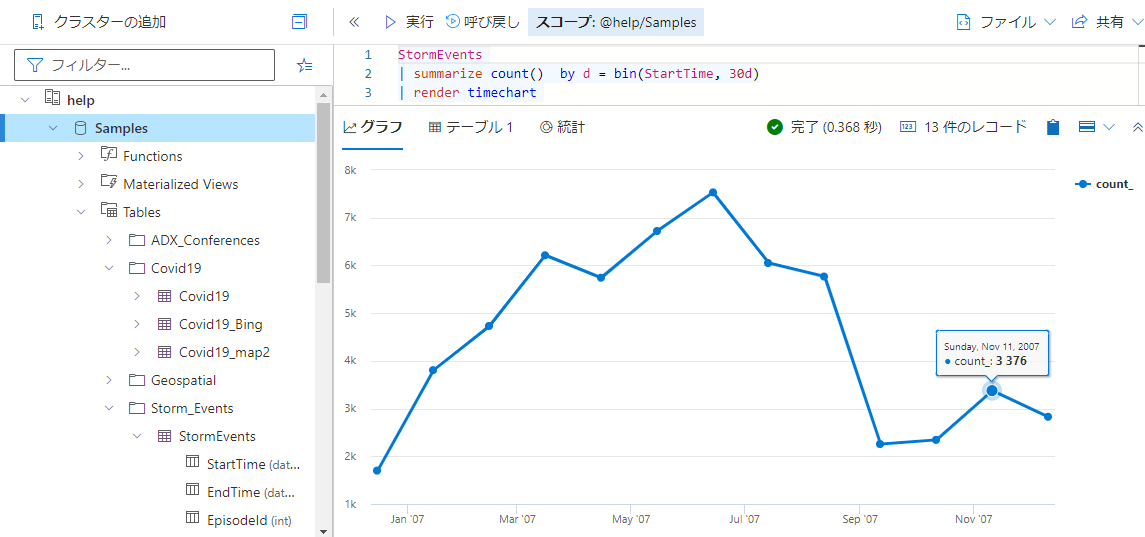
使用する際はLog Analyticsの「ログ」のメニューからKQLを書く窓を開くこともできるのですが、他に「Kusto.Explorer」というツールもあり、こちらを使うとデスクトップアプリケーションから様々な機能の助けを借りつつクエリを書くこともできます。SQL Serverに対するA5 SQLやSSMSみたいなものですね。
簡単に試せる環境があるのよ
また、KQLを簡単に試せる環境があります。
ここにはあらかじめデータが挿入された環境があり、KQLを打ち込むことでいくつかのテーブルから結果を出力することができます。
例えば初期状態だとサンプルのクエリとして
StormEvents | where StartTime >= datetime(2007-11-01) and StartTime < datetime(2007-12-01) | where State == "FLORIDA" | count
が入力されています。
この実行結果としてはCountに23が出力されます。
このクエリを基にして例えば最後の行のcountを外すとその23件のデータが全カラム表示されたり、projectを使うことで表示するカラムを絞り込むことが出来たりします。
ここで様々なクエリを試してみることができるので、様々なクエリを試してみましょう。
おわりに
KQLはLog Analyticsでログを確認するときによく使用するもので社内でも時々急に使うことになったりするのですが、キーワードが独特なので一見とっつきづらい感じがします。
多くの人は多かれ少なかれSQLを書いたり触れたりした経験はあると思うのですが、その知識をベースにしてKQLはこんな感じだよと説明したらわかりやすいのではないのではないのかというのがこの記事の試みです。
KQLを初めて使う!けどSQLは触ったことあるよという方の理解の助けになれば幸いです。